-
5-2_요약_Continuous_Bag_of_Words_CBOW.ipynb_단어와 타입 임베딩pytorch를 이용한 자연어입문 2024. 5. 10. 15:40
Data type
continuous(연속) - 이미지
discrete(이산) - 자연어
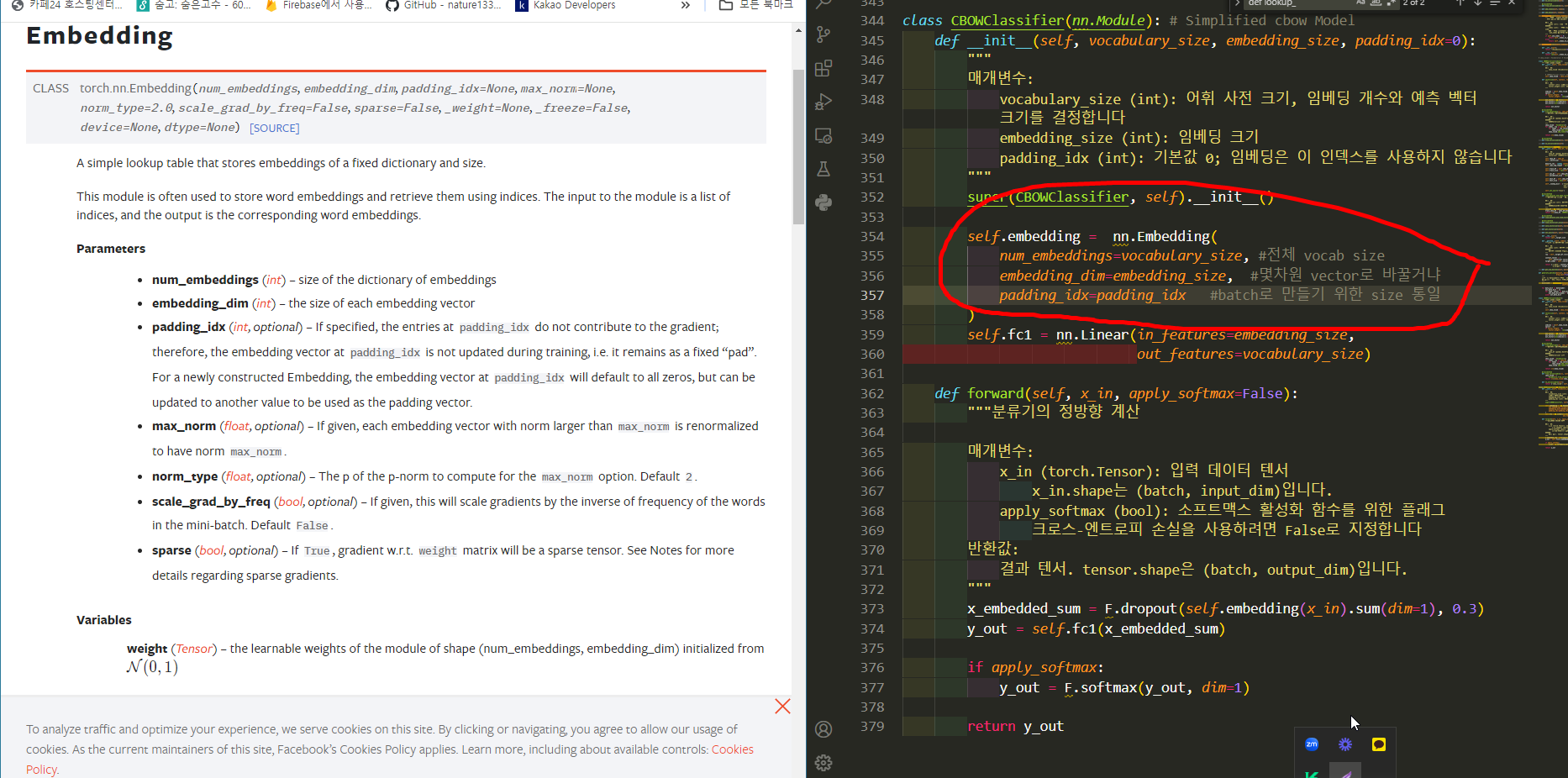
Embedding : 단어, 토큰의 벡터표현
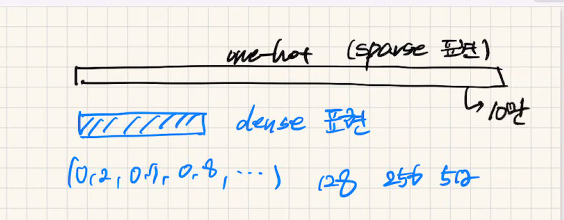
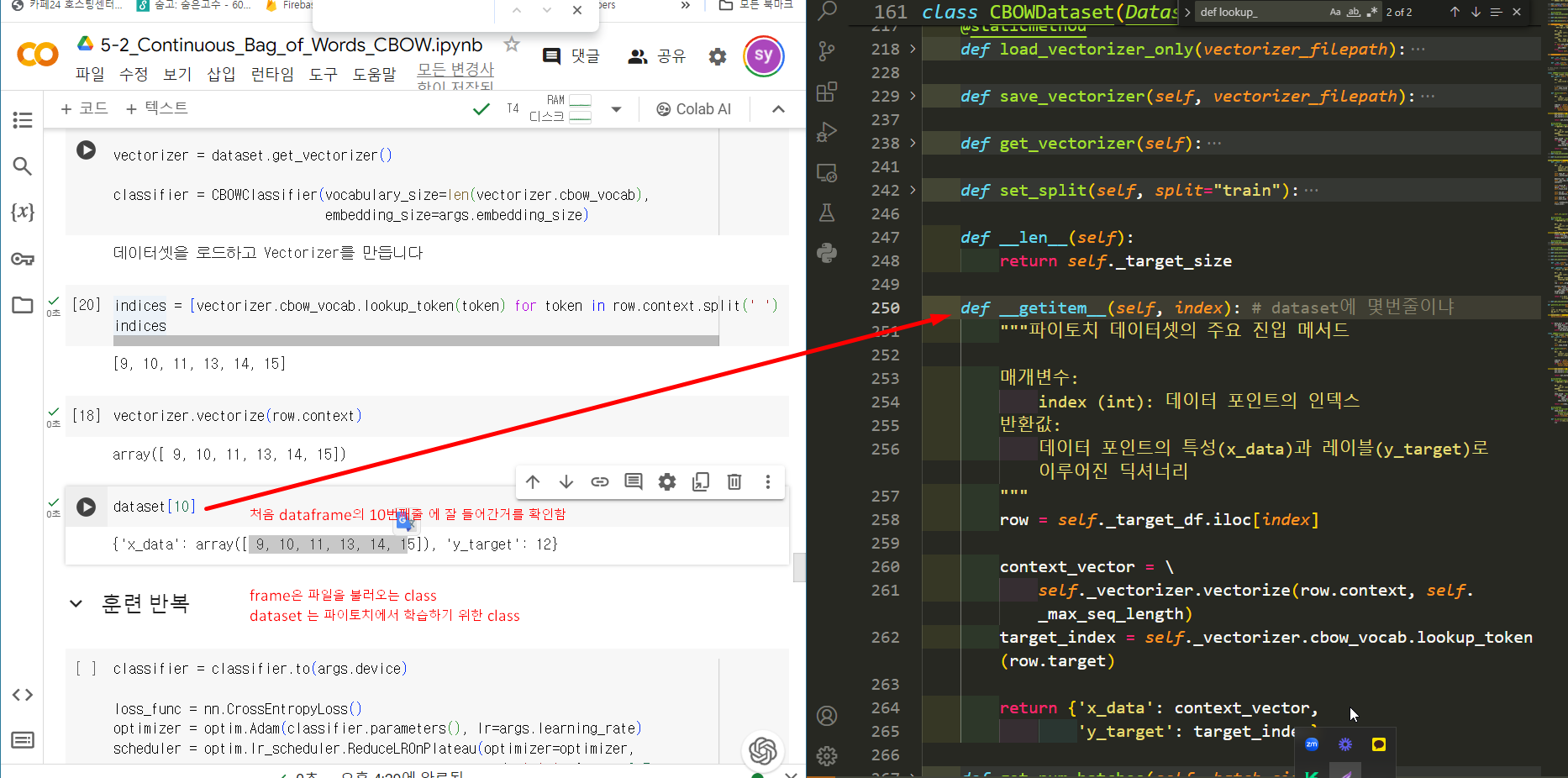
one hot vector로 단어를 표현하면
n개의 전체단어수 = vocab size = vector 크기 = vocab size

onehot vector의 문제-> sparse 표현(예 000001)
1. 계산문제 : size 너무 커서 비효율적
2. 통계적, 서로 관계 알기 어려움

onehot vector 해결점 -> dense표현으로 기존 10만(sparse표현)을 몇백단위로 줄여서 표현
1. 계산 줄어듬
2. 단어간 의미를 고려할수 있음.
3. 특정 task에 적합하도록 학습시킬수 있다.(backpropagation)
아래그림
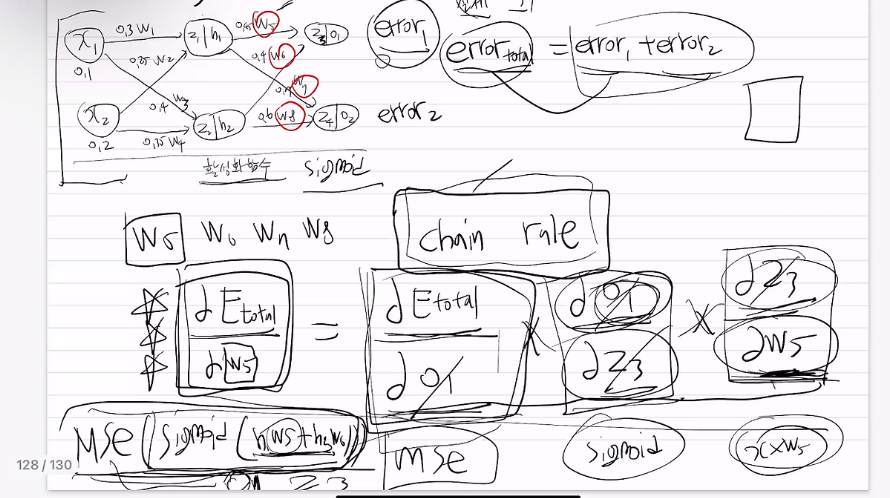
backpropagation으로 가중치 수정

Encoder: 데이터 입력시 변형해서 (보통은 압축하기도) 벡터출력하는 모델

아래그림
encoder는 tok1, tok2, ... tokn 를 압축해서 hidden vector로 나타낸것
decoder는 hidden vector를 다시 풀어서 자연어 문장으로 나타낸것


Embedding 종류
GLOVE, CBOW, Skip-gram
-> 문장내에 단어맞추기 embedding 가운데 보고 주변맞추기, 주변단어보고 가운데 맞추기(나온지 오래됨)
아래그림
Transformer - BERT - GPT
BERT - MLM(Masked LM), NSP(Next Sentence prediction)
MLM(Masked LM) - random하게 마스킹해서 진행
NSP(Next Sentence prediction) - 문장 2개 붙여놓고, 연속된 문장인지 아닌지 binary로 맞추기
GPT (Cousal LM-인과적 language model)
단어있으면 그전까지 주고, 그다음을 맞춰라
나는 학교에 ____

아래
Cross Entropy

====================
scholor 가 숫자 하나
vector 숫자 한줄
행렬 - vector를 2줄 이상
tensor - 3차원 이상 (1차원부터
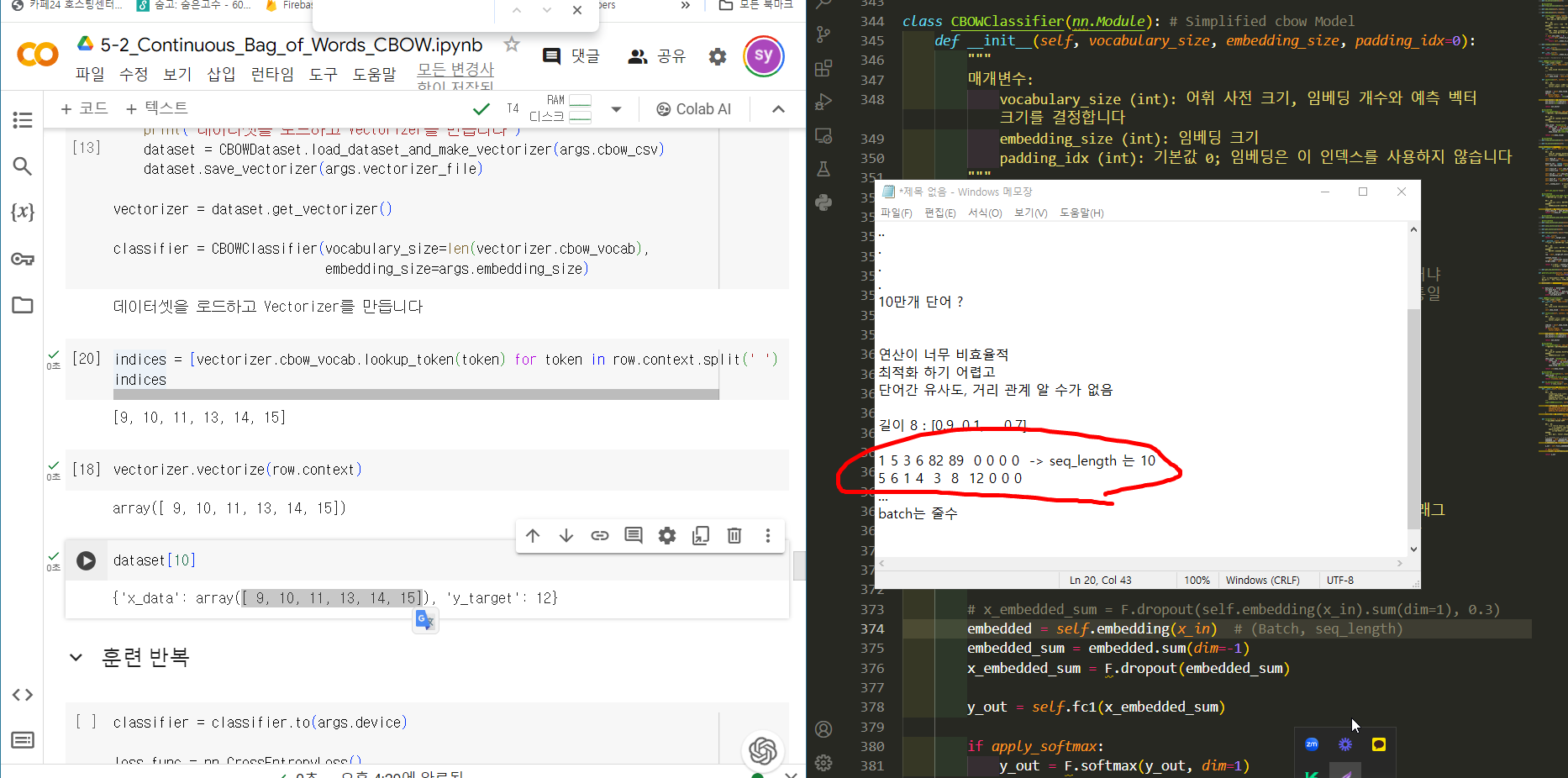
Vocab
apple [1, 0, 0, 0, 0, ...] -> 10만개 숫자
banana [0, 1, 0, 0, ..]
car [0, 0, 1, 0, 0, ...]
is
the
..
.
.
.
10만개 단어 ?
연산이 너무 비효율적
최적화 하기 어렵고
단어간 유사도, 거리 관계 알 수가 없음
길이 8 : [0.9, 0.1, ... 0.7]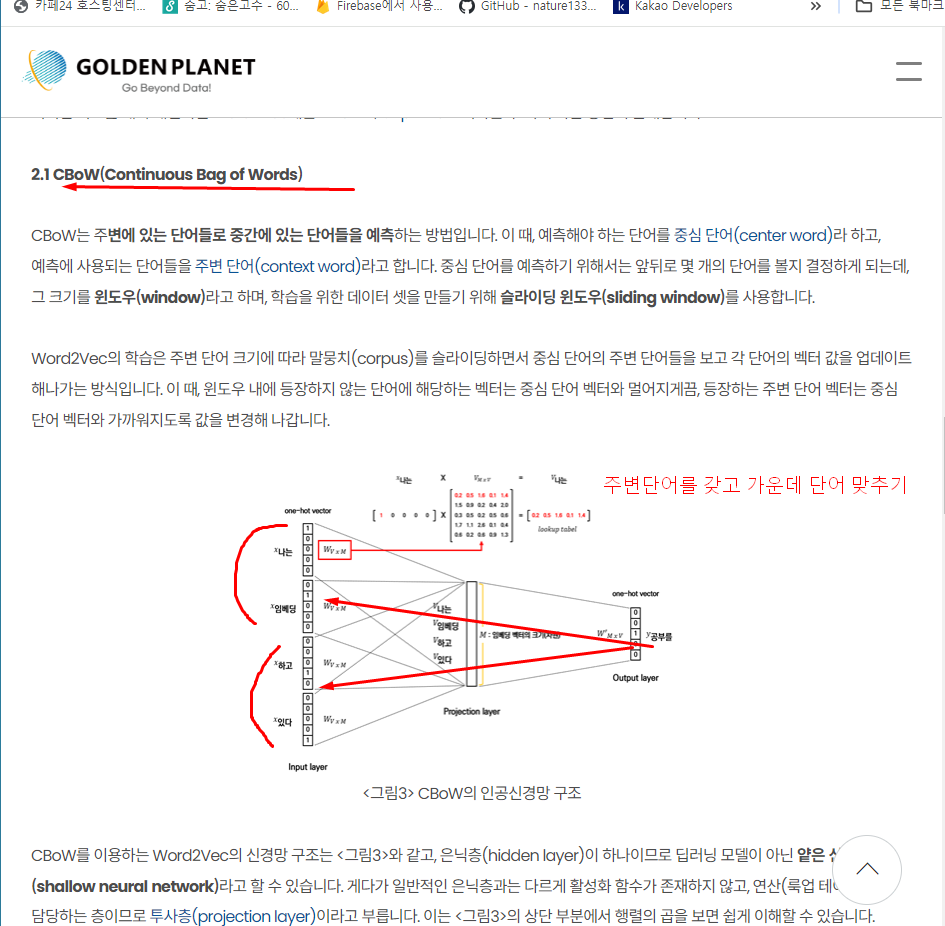



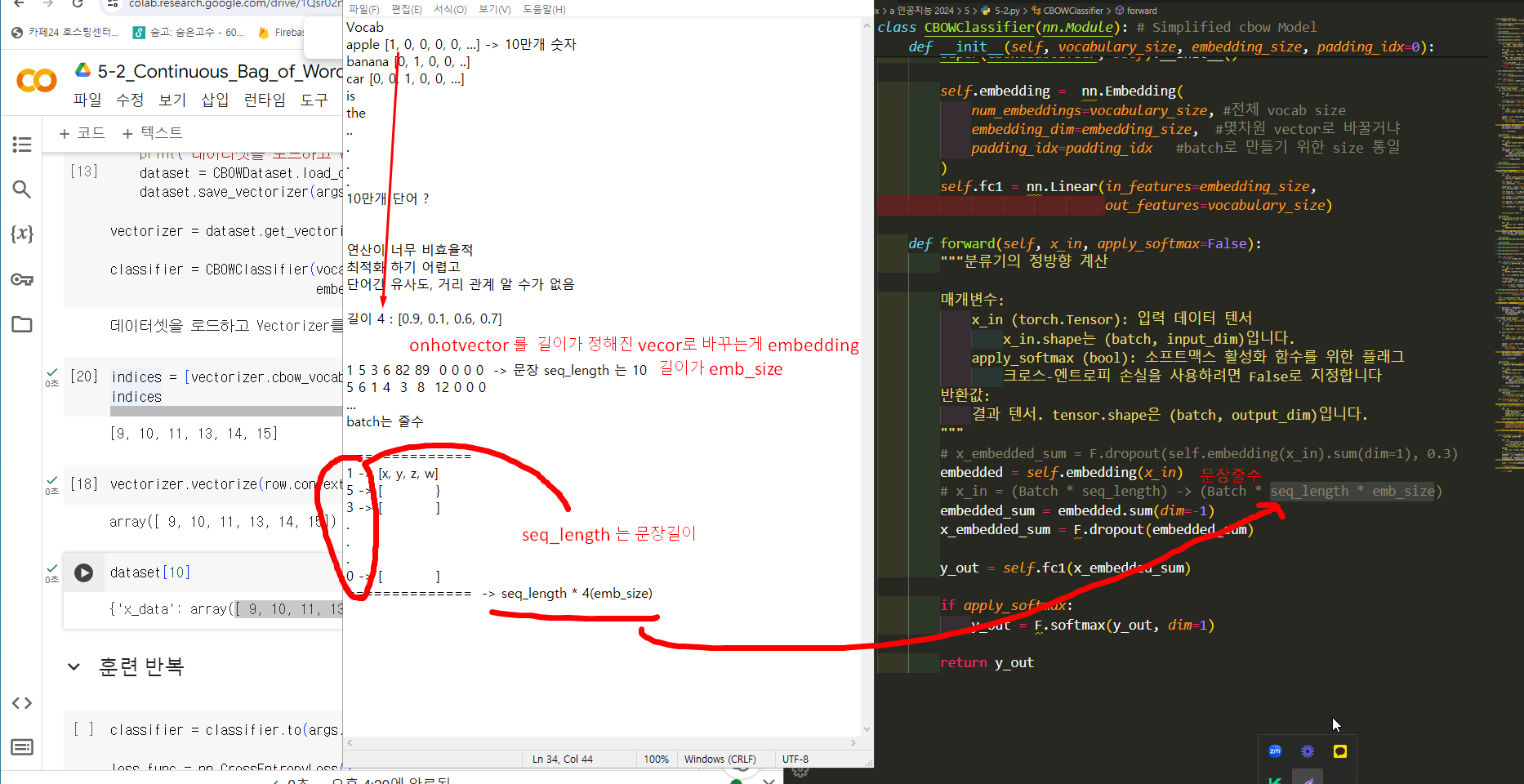

out_feature
모델의 출력결과 vector에서 제일 큰숫자를 보고 몇번째 있는지 보고
그 단어가 가운데 단어라고 모델이 예측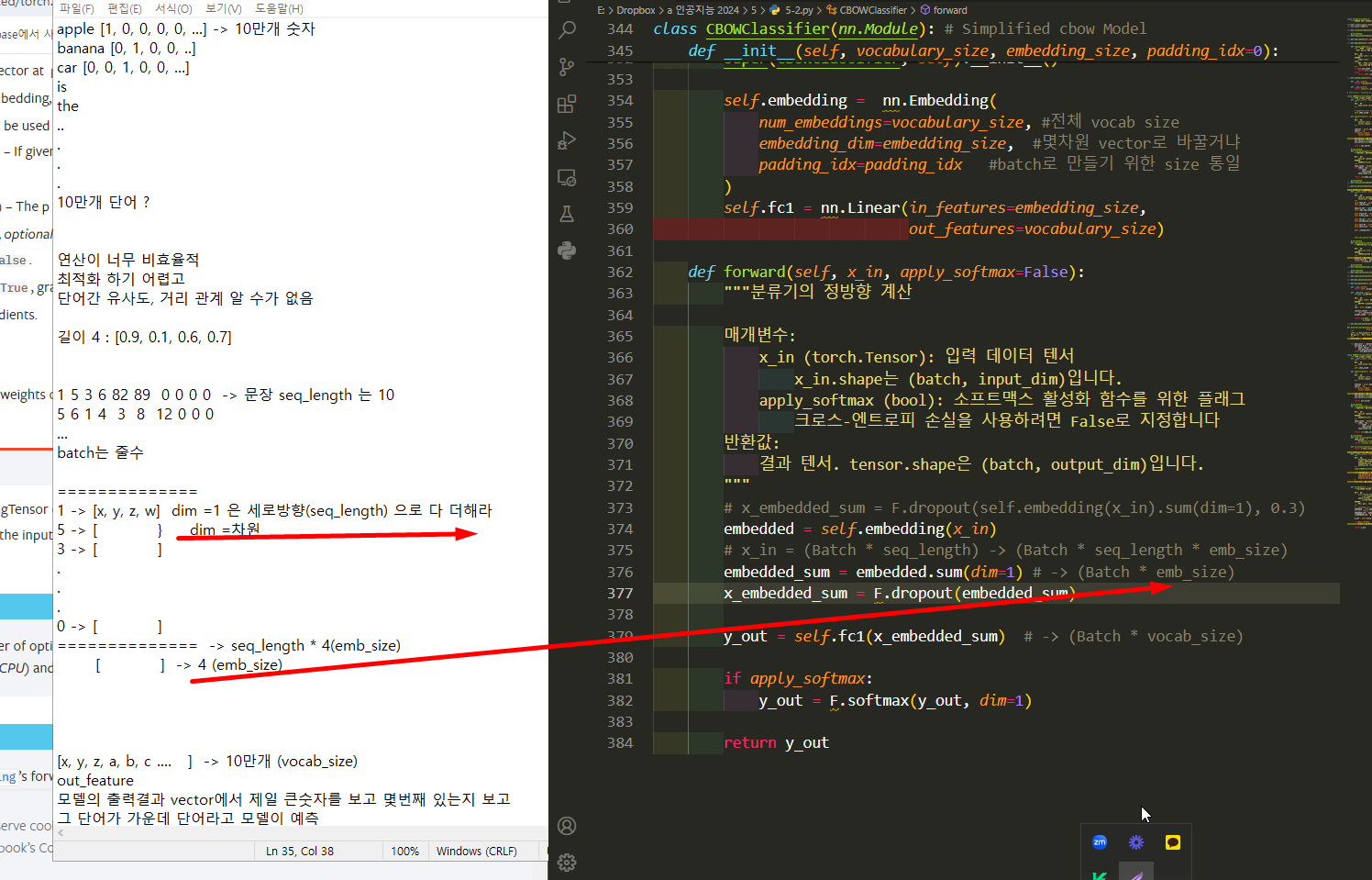
'pytorch를 이용한 자연어입문' 카테고리의 다른 글
6_요약_Surname_Classification_with_RNNs.ipynb (0) 2024.05.24 5-3_요약_new 분류 (0) 2024.05.17 4-3_요약_Classifying_Surnames_with_a_CNN.ipynb (1) 2024.04.20 4-2_요약_ Classifying_Surnames_with_an_MLP.ipynb_ 다층 퍼셉트론으로 성씨 분류하기 - overfitting 방지법 (데이터 늘리기, Early stopping(validation data), Weight Decay(가중치 감쇠), Dropout, Batch Normalization (0) 2024.04.19 4-1_요약_XOR_Problem2.ipynb_ 요약_20240403 (0) 2024.04.03