-
Hyper-CL 22 Sep 2024논문-한양대(김태욱교수님) 2024. 9. 22. 19:29
출처: 한양대 논문 Hyper-CL 22 Sep 2024
Introduction
가중치가 많으면 기억할수 있는 역량이 늘어남데이터가 적은데 가중치가 많아지면 overfitting이 일어나서 외워버리는 상태모델이 크다면 데이터도 많음
•Kaplan et al., 은 일반적으로 보다 큰 언어 모델이 더 좋은 성능을 가진다는 것을 알아냄•따라서 최근 언어 모델들은 계속해서 크기가 커지는 추세•이러한 트렌드에서 Embedding 모델 또한 벗어나지 않음•문장 Embedding을 만들때, 보다 큰 모델이 (일반적으로) 더 나은 Embedding을 만드는 것으로 생각됨•이렇게 만들어진 Embedding은 일반적으로 유사도 분석 등에 활용됨•예를 들어서, 두 문장의 Embedding이 서로 가깝다면, 이 두 문장은 비슷한 뜻을 가지고 있을 것으로 생각됨•하지만, 문장의 유사도는 보는 관점에 따라서 달라질 수 있음 (사람과 사람 소통시)•문장 1: A cyclist pedals along a scenic mountain trail, surrounded by lush greenery 산길에 자전거•문장 2: A hiker navigates through a dense forest on a winding path, enveloped by the tranquillity of nature 숲속에 걸어가기•관점 1: The mode of transportation•관점 2: The speed of travel아래그림)
언어모델은 비싸서 embedding(두문장의 유사도계산시) 사용
 •이러한 “조건부 유사도”는 단순한 Embedding 모델로는 구현하기가 힘듬•Pande et al., 은 현재 대다수의 문장 Embedding 모델들이 이러한 관점 차이를 제대로 반영하지 못한다는 것을 알아냄•이를 해결하기 위해 여러가지 새로운 모델 구조들이 제안됨•s1, s2 -> 문장 1, 2•c -> 조건 (관점) = condition
•이러한 “조건부 유사도”는 단순한 Embedding 모델로는 구현하기가 힘듬•Pande et al., 은 현재 대다수의 문장 Embedding 모델들이 이러한 관점 차이를 제대로 반영하지 못한다는 것을 알아냄•이를 해결하기 위해 여러가지 새로운 모델 구조들이 제안됨•s1, s2 -> 문장 1, 2•c -> 조건 (관점) = condition아래그림
문장을 단어화하거나 단어각각 embedding해서 합함.
 •공통적으로 s1, s2, c를 사용해 두 문장 사이의 유사도를 계산하는 과정•(기존은 단어를 embedding했지만 ,•요즘은 문장자체를 embedding)•문장전체를 단어화하거나•문장을 나눔•입력값들이 인코딩 되고 (CLS) 이후 여러 과정을 거쳐 유사도 계산
•공통적으로 s1, s2, c를 사용해 두 문장 사이의 유사도를 계산하는 과정•(기존은 단어를 embedding했지만 ,•요즘은 문장자체를 embedding)•문장전체를 단어화하거나•문장을 나눔•입력값들이 인코딩 되고 (CLS) 이후 여러 과정을 거쳐 유사도 계산
아래그림
세문장을 한번에 한줄에 만듬-> encoder(문장 embedding 모델- 문장을 embedding만드는 모델)
-> predictor(예측)하게 만듬 -> 유사도

아래그림 )
입력받는 벡터의 크기는 동일(제한됨)
1. 똑같은 embeeding으로 임의로 만듬(입력값 변경)
-> 일반적으로는 너무 긴거를 받거나 그이상은 자르거나
부족한입력값은 padding으로 채움- > 똑같은 embedding을 만든것
2. embedding 통과해서 고정된 크기의 vector로 바꿔준다.

아래그림
Embedding
문장, 단어 등 --> 고정된 크기의 vector로 바꿔준다.
vector -> 주어진 글의 의미를(어느정도) 포함
아래그림

모델의 embedding크기 고정 - 만드는사람이 결정

다시정리
목적:
임의의 문장,조건등을 동일한 크기의 vector로 변환
1. 긴거 자르고, 남는거 메꾸고 ( 중요한게 뒤에 오면 버려짐)
2. Embedding 모델을 쓰는거(아주많은 학습한 모델) (여러경우를 학습한 모델이라 보다 유연하게 대처)
아래그림
•Cross-Encoder / Bi-Encoder•공통점•주어진 문장과 조건을 같이 인코딩함•문장들과 조건의 상호작용을 직접적으로 학습할 수 있음 (보다 높은 성능 기대 가능)•차이점: cross encoder와 bi encoder 차이점•bi encode는 문장간의 상호작용은 학습이 힘듬.모든 경우의 수를 전부 계산해야 한다는 단점이 있음
따라서 훈련에 훨씬 많은 데이터가 필요함


아래그림)
또한 이미 계산된 값 (CLS 등)을 재사용하기가 어려움
아래그림
•그에 반해 Tri-Encoder는 각 문장과 조건을 따로 인코딩함•이후 각 문장과 조건을 합친 다음 (함수 g를 통해) 유사도 계산•이때 계산된 값들 (CLS 등)은 이후 재사용 가능 -> 훨씬 높은 효율•다만 Bi-Encoder에 비해 낮은 성능을 보이는데, 이는 문장과 조건 사이의 관계를 직접적으로 학습하지 못하기 때문연구목적
cross encodeor 는 너무 경우의 수가 많아서 학습하기 힘들어서 제외하고,
Bi-Encoder 와 Tri-Encoder 를 활용해서
•, Bi-Encoder의 성능은 유지하면서 Tri-Encoder의 효율을 유지하는 방법이 필요함•본 연구에서는, Tri-Encoder 구조를 개선해 Bi-Encoder 급의 성능을 낼 수 있는 방법을 제안함관점에 따라 embedding사이의 유사도 cosθ 가 달라짐노랑색일때랑, 파랑색일때랑 유사도가 달라짐아래그림
출처: C-STS


아래그림)

아래그림)
triencoder의 정확도를 높이기 위해
hypernetwork를 통해 주어진 조건에 대해 행렬을 만든후
문장1과 문장2에 곱했다.

Dataset(하나의 dataset)
•Hyper-CL은 두가지 데이터셋 (Task)을 사용해 각각 훈련되고 평가되었음•1. Conditional Semantic Textual Similarity (C-STS)•각 Entry는 문장 1, 문장 2, c_low, c_high 의 네가지 요소로 구성됨•문장 1과 문장 2는 c_high 의 조건에서는 매우 가깝고(높은유사도), 반대로 c_low(낮은유사도)의 관점에서는 멀리 떨어져 있음•이때 모델은 주어진 문장과 조건에 맞는 유사도를 계산해야 함아래그림
예시)
S1 = 숲에서 자전거를 탄다, S2 = 숲에서 걷는다.
Chigh = 주번풍경
Clow = 이동수단.
(S1, Chigh, S2) ---> 모델 ---> 높은 유사도
(S2, Clow, S2) ---> 모델 ---> 높은 유사도

아래그림
Experiment
•Hyper-CL은 Contrasive Learning을 통해 훈련됨•간단히 말하자면, 가까운 것들은 더욱 가깝게, 먼 것들은 더욱 멀도록 하는 것 •먼저 C-STS에서는•두개의 문장들은 c_high 가 주어졌을 때는 높은 유사도를 가져야 함•반대로, c_low 가 주어졌을 때는 낮은 유사도를 가짐•이를 바탕으로 Hyper-CL 훈련 진행 (역전파 등)•실제 Error 계산 공식 등의 세부적인 내용은 생략됨
•먼저 C-STS에서는•두개의 문장들은 c_high 가 주어졌을 때는 높은 유사도를 가져야 함•반대로, c_low 가 주어졌을 때는 낮은 유사도를 가짐•이를 바탕으로 Hyper-CL 훈련 진행 (역전파 등)•실제 Error 계산 공식 등의 세부적인 내용은 생략됨Experiment (C-STS)

아래그림
단점:
triencoder에서 조건을 hypernetwork를 적용해서 행열을 만든후
기존 문장 embedding에 내적해서
조건이 반영된 새로운 문장 embedding으로 하는데,
만약, 기존 문장 embedding이 엄청 큰 숫자가 되면,
곱해지는 조건을 hypernetwork를 적용해서 행열도 똑같이 커짐
그러면 hypernetwork도 커져야해서 (모델사이즈가 커짐)
비효율성(돈이 많이 듬)
 •이를 해결하기 위해 상대적으로 작은 Hypernetwork 두개를 만들고, 이 둘이 훨씬 작은 행렬 두개를 만들도록 함•이 Hypernetwork들은 h x k 행렬을 만드는데, 이때 k는 h보다 훨씬 작은 값임•만약 h가 10, k가 3라면, 원본 Hypernetwork는 10 x 10의 행렬을 만들었지만, 작은 모델들은 10 x 3를 만드는 것•이 두개의 작은 행렬들을 곱하면 (둘중 하나를 전치해서)•(10 x 3 행렬) x (3 x 10 행렬) -> 10 x 10 행렬•이러한 Hyper-CL 은 다양한 모델에 사용될 수 있음•연구진들은 다양한 Tri-Encoder 모델들에 Hyper-CL을 적용하고 차이점을 분석하였음•적용된 모델에는 Hyper-CL이 적혀 있으며, 만약 두개의 Hypernetwork로 나뉘었다면 h의 크기가 같이 적혀 있음
•이를 해결하기 위해 상대적으로 작은 Hypernetwork 두개를 만들고, 이 둘이 훨씬 작은 행렬 두개를 만들도록 함•이 Hypernetwork들은 h x k 행렬을 만드는데, 이때 k는 h보다 훨씬 작은 값임•만약 h가 10, k가 3라면, 원본 Hypernetwork는 10 x 10의 행렬을 만들었지만, 작은 모델들은 10 x 3를 만드는 것•이 두개의 작은 행렬들을 곱하면 (둘중 하나를 전치해서)•(10 x 3 행렬) x (3 x 10 행렬) -> 10 x 10 행렬•이러한 Hyper-CL 은 다양한 모델에 사용될 수 있음•연구진들은 다양한 Tri-Encoder 모델들에 Hyper-CL을 적용하고 차이점을 분석하였음•적용된 모델에는 Hyper-CL이 적혀 있으며, 만약 두개의 Hypernetwork로 나뉘었다면 h의 크기가 같이 적혀 있음아래그림
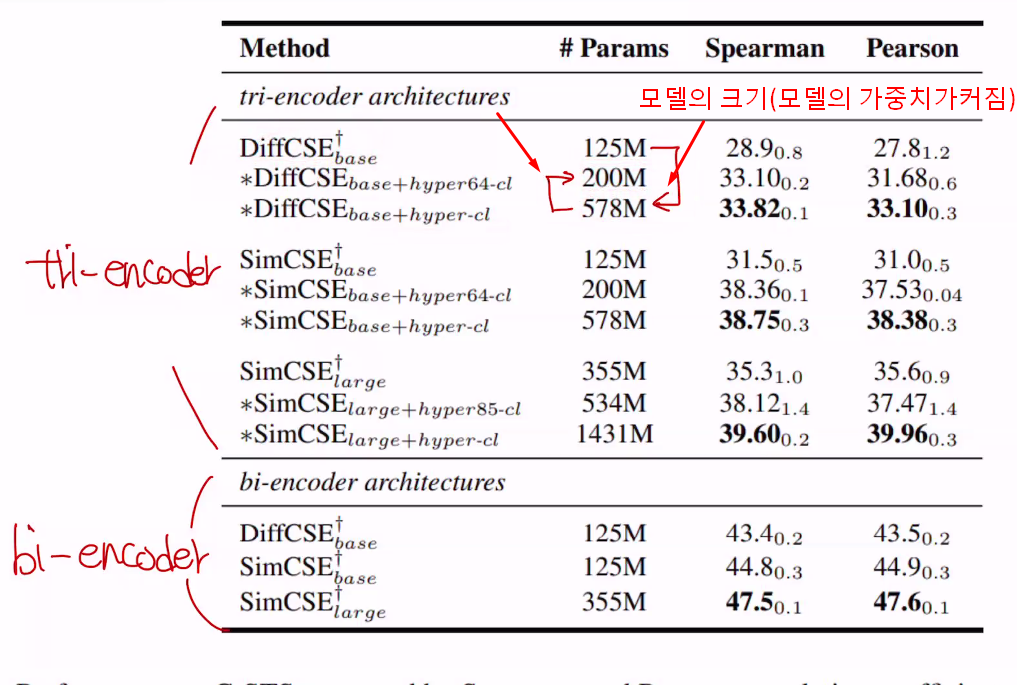
다른 연구에서 모델 3개 DiffCSE SimCSE(small, large) 를 가져와서 직접실험비교함.
tri-encoder hyper cl를 적용했고, 이는 너무 커져서 비효율적이어서
작은행렬 2개를 만들어서 곱했을때 원래행렬이 나오도록 한것
예) 1000x1000 -> 1000x64, 64x1000 -> 두개를 곱함


아래그림
임의의 두값사이 비례관계 - 맨왼쪽 정비례해서 값=1
역비례 - 값 = -1
중간 점들 비례관계 없으면 값 = 0
아래그림
•결과 표를 보면, Hyper-CL을 적용했을 때 Tri-encoder의 점수는 평균적으로 7.25가 올랐음•원래는 Bi-Encoder와 Tri-Encoder 사이에 13.3점의 차이가 있었지만, Hyper-CL을 적용했을 때는 이 차이가 6.05로 줄어듬•또한 이 결과는 두개의 작은 Hypernetwork를 사용했을때도 거의 변하지 않음 (효율성 증가)

두번째 task (Dataset)
2. Knowledge Graph Completion
•Knowledge Graph는 단어 그대로, 지식 (정보)를 그래프 형태로 나타낸 것•각 Entity (동물, 식물, 건물 등등) 사이의 관계들을 포함함 •Knowledge Graph에서, 어떠한 지식은 세가지 요소로 표현됨•Head, Relation, Tail (때때로 다른 용어가 사용되기도 함)•예를 들자면,•Da Vinci (Head)•Painted (Relation)•Mona Lisa (Tail)•이때 모든 지식을 담는 것은 불가능하므로, 기존에 알고 있는 내용으로부터 새로운 지식을 추론할 필요성이 있음•Head와 Relation, 또는 Relation과 Tail이 주어졌을 때 가장 적절한 요소를 예측하는 것 (다른 예측도 가능)•예시:•___, “is the capital city of”, “France”•“Seoul”, “is the capital city of”, ___
•Knowledge Graph에서, 어떠한 지식은 세가지 요소로 표현됨•Head, Relation, Tail (때때로 다른 용어가 사용되기도 함)•예를 들자면,•Da Vinci (Head)•Painted (Relation)•Mona Lisa (Tail)•이때 모든 지식을 담는 것은 불가능하므로, 기존에 알고 있는 내용으로부터 새로운 지식을 추론할 필요성이 있음•Head와 Relation, 또는 Relation과 Tail이 주어졌을 때 가장 적절한 요소를 예측하는 것 (다른 예측도 가능)•예시:•___, “is the capital city of”, “France”•“Seoul”, “is the capital city of”, ___아래그림

아래그림
•Hyper-CL은 Contrasive Learning을 통해 훈련됨•간단히 말하자면, 가까운 것들은 더욱 가깝게, 먼 것들은 더욱 멀도록 하는 것실제 존재하는 head와 tail 사이의 relation -> Chigh와 같은의미실제 존재하지 않는 head와 tail사이의 relation -> Clow와 같은의미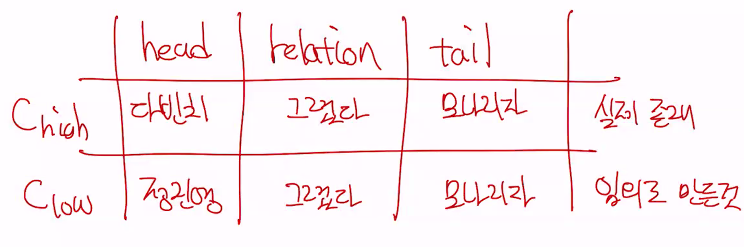

아래그림)
head나 tail를 추측해서 유사도가 높은것을 정답으로 함.

 •비슷하게, Knowledge Graph 예측에 대해서도 실험을 진행함•총 두개의 데이터셋 (WN18RR, FB15K-237) 을 사용하였음 -> 두개의 knowledge graph•실제 존재하는 Head, Relation, Tail이 주어졌을 때는 높은 유사도를 예측하도록 모델을 훈련시키고•반대로 랜덤하게 만들어낸 Head, Relation, Tail은 낮은 유사도를 가지도록 훈련
•비슷하게, Knowledge Graph 예측에 대해서도 실험을 진행함•총 두개의 데이터셋 (WN18RR, FB15K-237) 을 사용하였음 -> 두개의 knowledge graph•실제 존재하는 Head, Relation, Tail이 주어졌을 때는 높은 유사도를 예측하도록 모델을 훈련시키고•반대로 랜덤하게 만들어낸 Head, Relation, Tail은 낮은 유사도를 가지도록 훈련
아래그림
예측순위 숫자가 낮을수록 더 좋은 모델임.
단순 순위 평균을 하게되면 예측순위 숫자가
-> 나쁜모델 -> 더 높은 점수
-> 더 좋은 모델 ->이 낮은 점수
를 받게되서 직관적이지 않아서
역수취함

아래그림)
•Hits@n•실제 정답이 n 순위 안에 등장한 비율•Hits@5데이터셋에서, 실제 정답이 5위 안에 등장한 비율•예시 (데이터셋에 10개의 Entry가 있을때)•만약 6개의 Entry에서 실제 정답이 10 순위 안에 등장했으면•Hits@10 = 0.6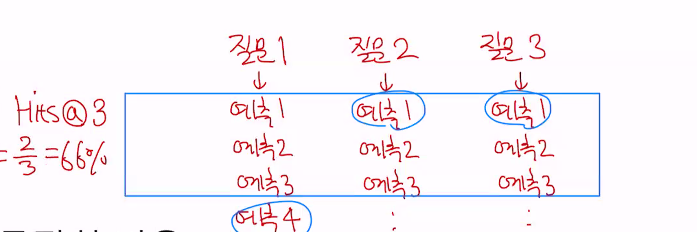
아래그림)
•Hyper-CL 을 적용한 SimKGC는 원본과 (원래는 Bi-Encoder) 비교했을때 큰 성능 차이가 나지 않음•또한, 두개의 Hypernetwork로 나눴을 때에도 큰 성능 저하가 일어나지 않았음SimKGC 는 선행연구에서 갖고온 bi-encoder 예측모델이고,아래그림) SimKGC 를 tri-encoder 로 개조했는데, 성능이 잘 안나옴

아래그림) Tri-encoder (SimKGC) hyper CL 적용하니, bi-encoder(SimKGC)만큼 성능이 나옴

아래그림) 하지만, Tri-encoder (SimKGC) hyper CL 를 적용하면 hypernetwork를 통해 행렬만들어서
기존 embedding에 곱한다.
이 과정에 더 많은 시간, 메모리등이 소요된다.(모델도 커지고, 비효율적)
Tri-encoder (SimKGC) hyper64cl은 원래 Tri-encoder (SimKGC) hyperCL을 두개로 쪼개서, 적용하면 성능을 약간 희생하고,
효율을 훨씬 높일수 있다.

 •추가적으로, C-STS와 KGC 둘에 대한 추론 시간 (실행 시간), Cache Hit rate, Cache(재활용, FAQ) 사이즈에 대한 분석을 진행함
•추가적으로, C-STS와 KGC 둘에 대한 추론 시간 (실행 시간), Cache Hit rate, Cache(재활용, FAQ) 사이즈에 대한 분석을 진행함
아래그림)•공통적으로, Bi-Encoder 모델보다 Tri-Encoder 모델이 훨씬 낮은 실행 시간을 보여줌•또한 더 높은 Cache-Hit rate 를 가짐 (이전에 계산했던 값을 효율적으로 재사용함) •마지막으로, Hyper-CL이 학습중 보지 못했던 조건 (관점)(새로운조건)에 대해 얼마나 좋은 성능을 보여주는지 마지막 평가 진행•C-STS 데이터셋 평가에서, Validation 셋을 학습에 포함된 조건들과 포함되지 않았던 조건들로 나눔 (기존에는 합쳐서 진행)•대략 26%의 Validation 셋이 학습에 포함되지 않았던 조건들이•이후 학습된 모델 (Hyper-CL 적용 / 미적용)을 두가지 Validation 셋에 각각 테스트아래그림)•전반적으로, Hyper-CL을 적용했을때 명확한 성능 향상이 이루어지는것을 확인할 수 있음•특히 학습때 보여주지 않았던 조건들에 대한 성능 향상이 두드러짐
•마지막으로, Hyper-CL이 학습중 보지 못했던 조건 (관점)(새로운조건)에 대해 얼마나 좋은 성능을 보여주는지 마지막 평가 진행•C-STS 데이터셋 평가에서, Validation 셋을 학습에 포함된 조건들과 포함되지 않았던 조건들로 나눔 (기존에는 합쳐서 진행)•대략 26%의 Validation 셋이 학습에 포함되지 않았던 조건들이•이후 학습된 모델 (Hyper-CL 적용 / 미적용)을 두가지 Validation 셋에 각각 테스트아래그림)•전반적으로, Hyper-CL을 적용했을때 명확한 성능 향상이 이루어지는것을 확인할 수 있음•특히 학습때 보여주지 않았던 조건들에 대한 성능 향상이 두드러짐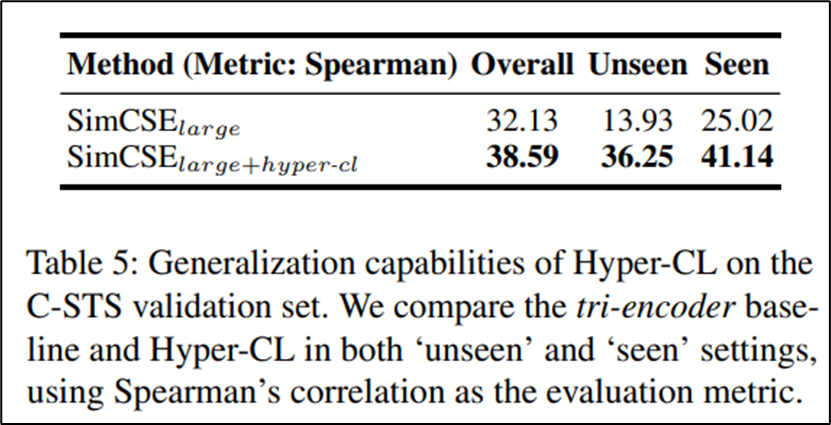
Conclusion
•Embedding을 통해 문장간 유사도를 계산할 수 있음•다만 일반적인 Embedding 모델은 보는 관점에 따른 유사도 차이를 잘 고려하지 못함•이를 해결하기 위해 여러 모델들이 제안되었음•이때 Bi-Encoder는 Tri-Encoder에 비해 상대적으로 성능이 높지만 효율이 떨어짐•이를 해결하기 위해 본 연구는 Hyper-CL을 제안하였고, 이를 적용한 Tri-Encoder는 효율을 유지하며 Bi-Encoder의 성능을 상당히 따라잡는데 성공함Limitations
•본 연구에서는 (Embedding) Encoder에만 집중하였으며, Decoder에는 관심을 주지 않았음•또한 보다 다양한 모델과 데이터셋을 통한 후속 연구 필요