-
Explicit test: BLEU카테고리 없음 2024. 9. 5. 19:06
Explicit test: BLEU (precision)
•1-gram BLEU score:••Candidate 1: "The cat sleeps peacefully."••Reference 1: "The cat rests quietly."•Reference 2: "A cat naps peacefully."•Reference 3: “A cat sleeps soundly at night."••BLUE: (Candidate 의 총 단어 수) / (Reference에 등장한 단어 수)4 / 4 = 1Explicit test: ROGUE(recall) - recallExplicit test: BLEU
•단점:•계산 과정에서 Precision만 고려하고, Recall은 무시함•예를 들자면, 전문가가 만든 글에서 나온 단어들이 몇 개나 후보 글에 있는지는 무시됨•또한 일반적으로 Exact Match만 고려함 (활용형 고려 X)•따라서 비슷한 뜻을 가지지만 다른 단어를 쓴 경우 낮은 점수를 받을 수 있음••또한 BLUE 점수 계산은 Reference 텍스트의 질에 크게 의존함-> 항상 이러한 질좋은 Reference가 존재하지는 않음
Explicit test: Benchmarks
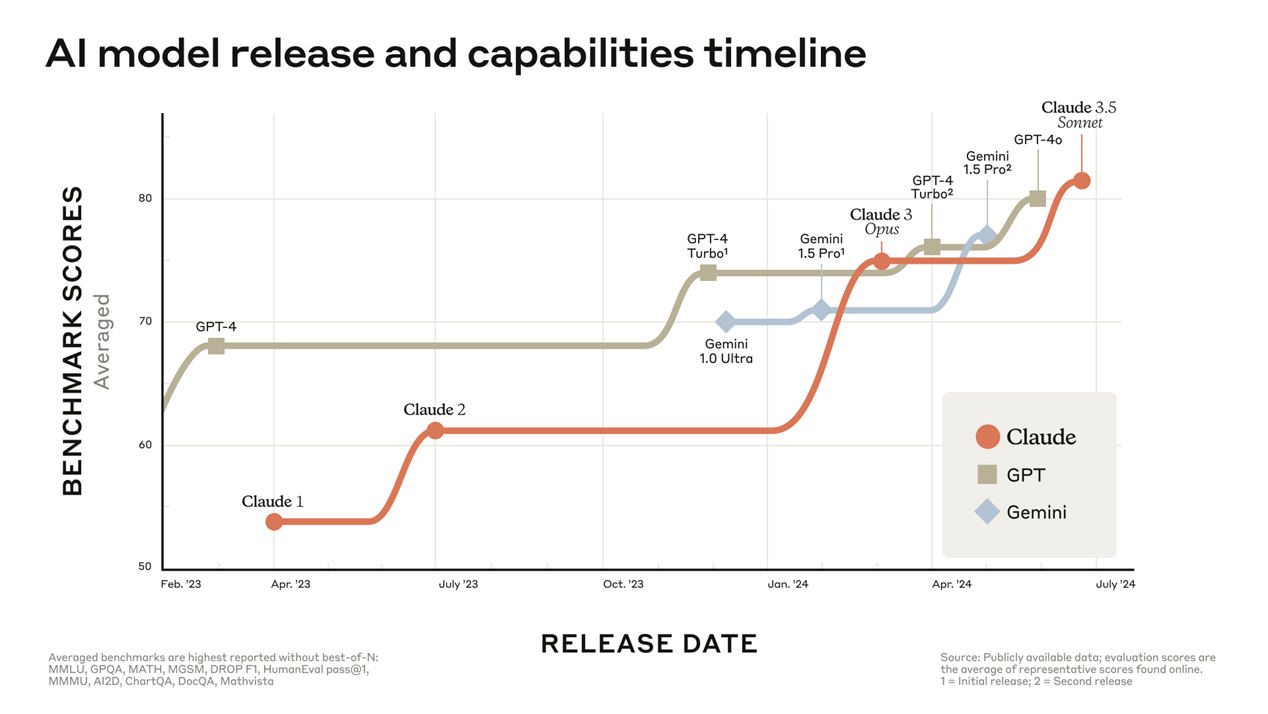 •Lianmin et al., 은 검증된 (훌륭한) 언어모델이 상대적으로 뒤떨어지는 언어모델의 벤치마크 답을 채점할 수 있음을 보임•검증된 언어모델 (GPT-4 등)은 사람과 거의 동일한 채점 결과를 보여줌•따라서 일반적으로 벤치마크는 연구자가 직접 채점하거나, 아니면 이러한 언어 모델을 사용해 채점함•답변의 정확도 (Truthfulness) 벤치마크 예시
•Lianmin et al., 은 검증된 (훌륭한) 언어모델이 상대적으로 뒤떨어지는 언어모델의 벤치마크 답을 채점할 수 있음을 보임•검증된 언어모델 (GPT-4 등)은 사람과 거의 동일한 채점 결과를 보여줌•따라서 일반적으로 벤치마크는 연구자가 직접 채점하거나, 아니면 이러한 언어 모델을 사용해 채점함•답변의 정확도 (Truthfulness) 벤치마크 예시 •일반적으로 보다 다양한 데이터셋으로 학습한 모델은 정확하지 않은 답을 만들어 낼 확률 또한 높음•단순하게 생각해서, 인터넷에는 정확한 정보도 있지만 부정확한 정보 또한 매우 많음•따라서 이런 데이터로 단순히 학습한 경우 사실과 다른 정보를 말할 가능성이 있음•언어 모델은 단순히 주어진 데이터를 바탕으로 확률을 계산할 뿐, 실제로 사람과 같이 “이해“ 하고 있지 않음.•간단히 말해서, 언어 모델은 단순히 들은 말을 따라하는 아이와 같으며, 어떤게 사실인지를 알지 못함.input -> 가장 유사한 output( 데이터셋) : 정답이 아닐수있음•이러한 현상을 흔히 Hallucination (환각)이라고 함•언어 모델은 (특히 LLM) 잘못된 정보를 말하거나, 실제 존재하지 않는 대상을 언급하거나, 어떠한 대상을 잘못 설명하거나 함•ChatGPT에게 특정 주제에 대한 논문을 찾아 달라고 했는데, 존재하지 않는 논문을 알려줘서 한참 찾은 적이 있음언어 모델의 정확도를 검사하는 것은 매우 중요 (특히 대중들에게 사용될 것으로 예상될 때)•상식 (Commonsense) 벤치마크 예시
•일반적으로 보다 다양한 데이터셋으로 학습한 모델은 정확하지 않은 답을 만들어 낼 확률 또한 높음•단순하게 생각해서, 인터넷에는 정확한 정보도 있지만 부정확한 정보 또한 매우 많음•따라서 이런 데이터로 단순히 학습한 경우 사실과 다른 정보를 말할 가능성이 있음•언어 모델은 단순히 주어진 데이터를 바탕으로 확률을 계산할 뿐, 실제로 사람과 같이 “이해“ 하고 있지 않음.•간단히 말해서, 언어 모델은 단순히 들은 말을 따라하는 아이와 같으며, 어떤게 사실인지를 알지 못함.input -> 가장 유사한 output( 데이터셋) : 정답이 아닐수있음•이러한 현상을 흔히 Hallucination (환각)이라고 함•언어 모델은 (특히 LLM) 잘못된 정보를 말하거나, 실제 존재하지 않는 대상을 언급하거나, 어떠한 대상을 잘못 설명하거나 함•ChatGPT에게 특정 주제에 대한 논문을 찾아 달라고 했는데, 존재하지 않는 논문을 알려줘서 한참 찾은 적이 있음언어 모델의 정확도를 검사하는 것은 매우 중요 (특히 대중들에게 사용될 것으로 예상될 때)•상식 (Commonsense) 벤치마크 예시 •사람은 경험을 통해 “상식“을 얻음•하지만 언어 모델은 이러한 경험을 하는 것이 불가능함••언어 모델은 마치 방에서 책만 읽은 사람과 유사함•책에 나온 정보는 누구보다 잘 알지만, 실제로 어떠한 대상을 본 적은 없음•요즘 나오는 LLM들은 비교적 상식 문제를 잘 맞추는 편•이 외에도 많은 벤치마크들이 있으며, 실시간으로 많은 연구 논문 또한 발표되고 있음••새로 발표되는 언어 모델의 경우 유명한 벤치마크 성능을 기재하는 것이 일반적••만약 많은 언어 모델들이 특정 벤치마크를 잘 풀게 되면 (변별력이 없어지면), 그 벤치마크는 잘 안 쓰이게 됨•
•사람은 경험을 통해 “상식“을 얻음•하지만 언어 모델은 이러한 경험을 하는 것이 불가능함••언어 모델은 마치 방에서 책만 읽은 사람과 유사함•책에 나온 정보는 누구보다 잘 알지만, 실제로 어떠한 대상을 본 적은 없음•요즘 나오는 LLM들은 비교적 상식 문제를 잘 맞추는 편•이 외에도 많은 벤치마크들이 있으며, 실시간으로 많은 연구 논문 또한 발표되고 있음••새로 발표되는 언어 모델의 경우 유명한 벤치마크 성능을 기재하는 것이 일반적••만약 많은 언어 모델들이 특정 벤치마크를 잘 풀게 되면 (변별력이 없어지면), 그 벤치마크는 잘 안 쓰이게 됨•허
 •장점:•언어 모델들의 성능을 객관적으로 비교할 수 있음•사람들한테는 정말 쉬운문제가 언어모델은 굉장히 어려워할수있음•특별한 전문 지식 없이도, 일반 대중이 바로 테스트 결과를 이해할 수 있음 (Perplexity is 0.8 은 관련 지식이 필요하지만, 상식 테스트 문제는 일반 대중들도 쉽게 풀 수 있음)다양한 벤치마크가 존재하며, 각각 다른 분야를 테스트함종합적인 성능을 평가하기에 좋음•단점:•벤치마크는 다른 방법들 (Perplexity, BLEU) 등에 비해 많은 시간이 필요하고, 검증된 언어 모델로 채점하는 것도 비쌈•또한 대부분의 벤치마크는 영어로 작성되어 있음. 다른 언어로 훈련된 언어 모델을 평가하기 위해서는 번역을 해야 함•이때 번역이 잘 되었나 검증하는 과정도 필수•때때로, 오래되고 유명한 벤치마크의 경우 언어 모델의 훈련 데이터 수집 과정에 포함될 수도 있음 – 벤치마크의 정답을 포함할수있음.벤치마크 결과가 원래 성능보다 높게 나올 것
•장점:•언어 모델들의 성능을 객관적으로 비교할 수 있음•사람들한테는 정말 쉬운문제가 언어모델은 굉장히 어려워할수있음•특별한 전문 지식 없이도, 일반 대중이 바로 테스트 결과를 이해할 수 있음 (Perplexity is 0.8 은 관련 지식이 필요하지만, 상식 테스트 문제는 일반 대중들도 쉽게 풀 수 있음)다양한 벤치마크가 존재하며, 각각 다른 분야를 테스트함종합적인 성능을 평가하기에 좋음•단점:•벤치마크는 다른 방법들 (Perplexity, BLEU) 등에 비해 많은 시간이 필요하고, 검증된 언어 모델로 채점하는 것도 비쌈•또한 대부분의 벤치마크는 영어로 작성되어 있음. 다른 언어로 훈련된 언어 모델을 평가하기 위해서는 번역을 해야 함•이때 번역이 잘 되었나 검증하는 과정도 필수•때때로, 오래되고 유명한 벤치마크의 경우 언어 모델의 훈련 데이터 수집 과정에 포함될 수도 있음 – 벤치마크의 정답을 포함할수있음.벤치마크 결과가 원래 성능보다 높게 나올 것