-
Bert 이후 모델 (Transfomer-XL, GPT2, XLNet)practice_최신트랜드 논문 2024. 10. 12. 13:40
Q. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding" 논문의 주요 기여와 BERT 모델의 작동 방식이 뭔가요
A. BERT는 Bidirectional Context를 고려한, transformer 모델을 만들었다.
사전학습 모델로써 masked language modeling, next sentence prediction 두작업을 이용해서,
사전학습을 진행했다. 이렇게 해서 다양한 task에서 좋은 성능을 보여줬다.
Q: "XLNet: Generalized Autoregressive Pretraining for Language Understanding" 논문에서 소개한 XLNet의 주요 장점과 BERT와의 차이점이 무엇인가요.
A. AUTOREGRESSIVE 방식과 AUTOENCODING 방식의 장점들만을 결합하기 위해서
Permutation (순열) 모델링을 썼다.
장점: Bidirectional 한 문맥을 고려하면서도, 독립가정이 필요없는 모델링을 할수 있었다.
경우의수 - 순열(permutation), 조합
이 문제는 경우의수 = 순열

Transformer-XL
Problem in the vanilla Transformer language model
(기존 transformer모델)
기존 transformer모델의 문제점: 모델은 사전 정의된 컨텍스트 길이를 넘어서는 장기 종속성을 포착할 수 없습니다.
• Context fragmentation: The model cannot capture any longer-term dependency beyond the predefined context length
아래그림) 길이가 4까지 밖에 못들어간다.


아래그림)
• Transformer-XL(초장)의 훈련 및 평가
• 세그먼트 수준 재귀 메커니즘: 이전 세그먼트에서 얻은 숨겨진 상태 재사용(앞의 segment의 hidden state갖고와서 쓴다)
• 새로운 위치 인코딩 체계: 절대 위치 인코딩이 아닌 상대 위치 인코딩기존 transformer모델의 문제점: 모델은 사전 정의된 컨텍스트 길이를 넘어서는 장기 종속성을 포착할 수 없습니다.
문제점 극복방법
Training and evaluation of Transformer-XL (extra long)
• Segment-level recurrence mechanism: reuse the hidden states obtained in previous segments
• Novel positional encoding scheme: relative position encoding rather than absolute ones
GPT2
GPT 2 모델은 GPT1보다 모델을 키움


• A Big transformer LM
• Trained on 40GB of text
• Quite a bit of effort going into making sure the dataset is good quality
• Take webpages from reddit links with high karma
• Language model can perform down-stream tasks in a zero-shot setting
– without any parameter or architecture modification
zero-shot setting - pretrain(다음단어맞추기) 만 하고 fine tuning은 안하고 task(요약)하기
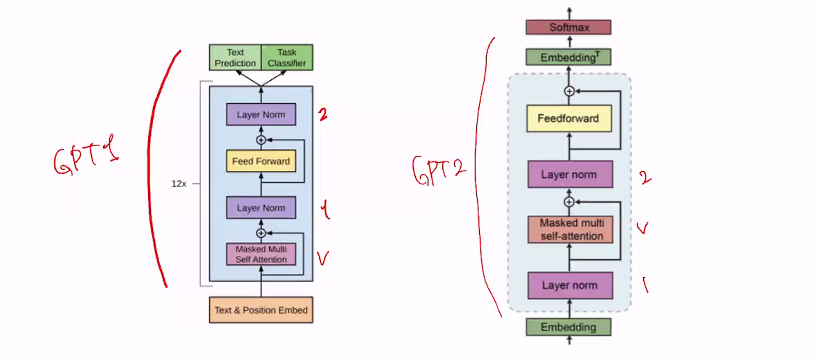
GPT2는 GPT1에 비해 구조 좀 바꾸고 모델 사이즈 아주 많이 키움 zero shot setting함
fine tuning안해도 능력커짐

ERNIE
지식 통합을 통한 향상된 표현
• 지식 마스크 전략으로 향상된 언어 표현을 배우도록 설계--> 의미를 가진 구문을 통으로 Masking 함
• Enhanced Representation through Knowledge Integration
• Design to learn language representation enhanced by knowledge masking strategies

아래그림) 구문으로 맞추기 했을때 ERNIE가 BERT에 비해 잘맞춤

XLNet
transformer-xl을 갖고 만듬 - 논문리젝되서 다시 만든것

P(A,B) = 동시에 일어날 확률
P(A|B)P(B) = (B가 주어진 가정하에 A가 일어날확률) x (확률B)




Autoregressive(AR) Language Modeling
• Can factorize the likelihood into a product p(x) = 곱하기 (왼쪽) 을 오른쪽(곱하기 여러 개로 나눔) -> 인수분해
• Unidirectional (다음단어맞추기 해서 오른쪽으로만 감)
Autoencoding(AE) Language Modeling
• Cannot factorize the likelihood into a product p(x)
• Bidirectional

아래그림) pretraining
Autoregressive(AR) - (GPT)
Pros.1: Can factorize the likelihood into a product p(x)
Cons.1: Cannot consider bidirectional contexts since it is unidirectional
Autoencoding(AE) – (BERT)
Pros.1: Can consider bidirectional contexts
Cons.1: Cannot factorize the likelihood into
a product à It assumes independency
Cons.2: <MASK> token is absent during finetuning time

아래그림)
Bert 모델은 독립적으로 가정하고 모델링했지만, 실제로는 정확하지는 않다.

아래그림) 순열로 구함
bidirectional contexts !
Can factorize
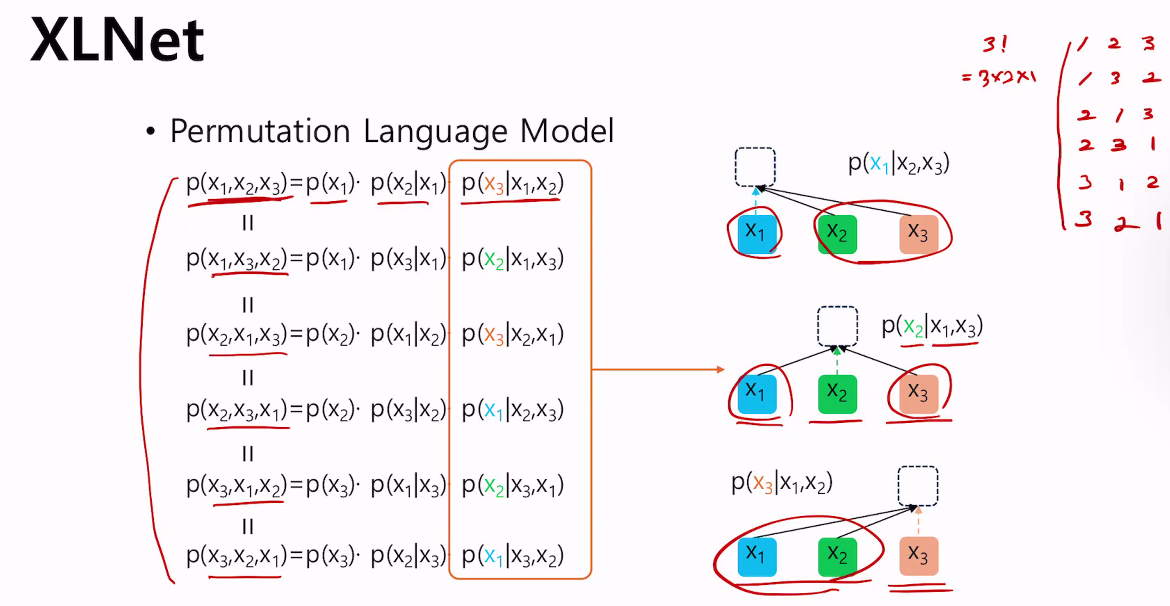
아래그림) Bidirectional 이상하지만, 확실히 Bidirectional 고려가능함, 문장 통째로 이해가능


'practice_최신트랜드 논문' 카테고리의 다른 글
T5 (1) 2024.10.12 RoBERTa (0) 2024.10.12 GPT (다음단어맞추기가 핵심) (1) 2024.10.07 Bert (0) 2024.10.04