-
Distributed Representations of Words and Phrases and their Compositionality (Word2Vec)논문리뷰 2024. 8. 30. 11:55
논문 리뷰시간 = 3일(12~16시간)
퀴즈 시간(서머리시간) = 1일 (3~4시간)
5~6 강의 = 24일
랩실 논문 리뷰
임베딩(Embedding) 이란
•단어를 벡터로 바꾼 것•단어/문장간 관련도 계산•의미적/문법적 정보 함축•이상적으로, 비슷한 단어는 비슷한임베딩을 가져야 함
임베딩(Embedding)
단어를 벡터로 바꾼 것 단어/문장간 관련도 계산의미적/문법적 정보 함 이상적으로, 비슷한 단어는 비슷한 임베딩을 가져야 함===============
summary
===================
•Embedding 이란 무엇인가?è단어를 벡터로 나타낸 것èEmbedding은 단어의 의미적/문법적 정보를 포함함è비슷한 단어는 비슷한 Embedding을 가져야 함èèEmbedding은 단어들 사이의 유사도를 계산할 때 사용할 수 있음
유사도 높은 단어를 추천

 정적 embedding,문맥과 무관하나 매우 효율적동적 embedding비효율적이지만 성능 훌륭
정적 embedding,문맥과 무관하나 매우 효율적동적 embedding비효율적이지만 성능 훌륭 è만약 모델이 잘 예측할 경우, 그 모델의 가중치는 모델이 학습한 단어의 뜻을 포함하고 있을 것임가중치를 임베딩으로 사용
è만약 모델이 잘 예측할 경우, 그 모델의 가중치는 모델이 학습한 단어의 뜻을 포함하고 있을 것임가중치를 임베딩으로 사용
소리가 입력이면 귀만 상관있음 - 그래서 가중치가 단어의 의미가 있다 생각함

•Continuous Bag of Words
•주변 단어를 받아서 중간 단어를 예측해보자•Skipgram
•중간 단어를 받아서 주변 단어를 예측해보자
구 들을 단어로 추측함. 단어의 결합으로는 뜻이 안나와서

N-gram
uni gram - 1 단어
bi gram - 2단어
sliding window 옆에 있는것
n- gram 의 단점 : 학습해야할 단어의 수가 어마어마 하게 늘어남 -> 학습시간 늘어나고, 메모리에 다 넣을수가 없음 (dataset이 너무 커서)
 •어떤 단어 w_i 와 w_j 가 있을 때, 이 둘이 phrase인지 아닌지는 아래의 점수 계산 식을 활용함
•어떤 단어 w_i 와 w_j 가 있을 때, 이 둘이 phrase인지 아닌지는 아래의 점수 계산 식을 활용함
 •δ는 0이라고 가정했을 때(기준점일때) apple pie가 cherry pie보다 점수가 높아서 apple pie가 phrase일 가능성이 높아짐
•δ는 0이라고 가정했을 때(기준점일때) apple pie가 cherry pie보다 점수가 높아서 apple pie가 phrase일 가능성이 높아짐
threshold 기준으로 원하는 phrase를 찾음
정말 확실한값을 찾고싶을때는 threshold를 높임
다양한거를 찾고싶을때는 threshold를 낮춤 (가끔 붙어나오는 단어도 값으로 취급가능)

===================

임베딩간의 유사도
비슷한 단어는 비슷한 임베딩을 가짐 다양한 유사도 측정 기법이 있음 (코사인 유사도 등)
정적 임베딩
각 단어마다 고정된 임베딩을 가짐 단어의 임베딩은 단어의 문맥과 무관계함 예시: 애플 파이 vs 애플 스마트폰정적 임베딩은 매우 빠르지만 문맥을 담지 못함Word2Vec, Glove, FastText 등이 있음
문맥 임베딩
•각 단어마다 문맥을 고려한 임베딩을 가짐 이전의 예시에서, 애플은 각기 다른 임베딩을 가질 것임거대 언어 모델 (LLM) 들은 모두 문맥 임베딩을 만들거나 아니면 문맥 임베딩에 기반함예를 들자면, 어떠한 문장을 넣었을 때 이걸 문맥 임베딩들로 변환해 줌
Word2Vec: CBOW
단어들을 One-hot 인코딩으로 변환함 One-hot 벡터의 크기는 단어의 수와 동일함
Word2Vec: CBOW
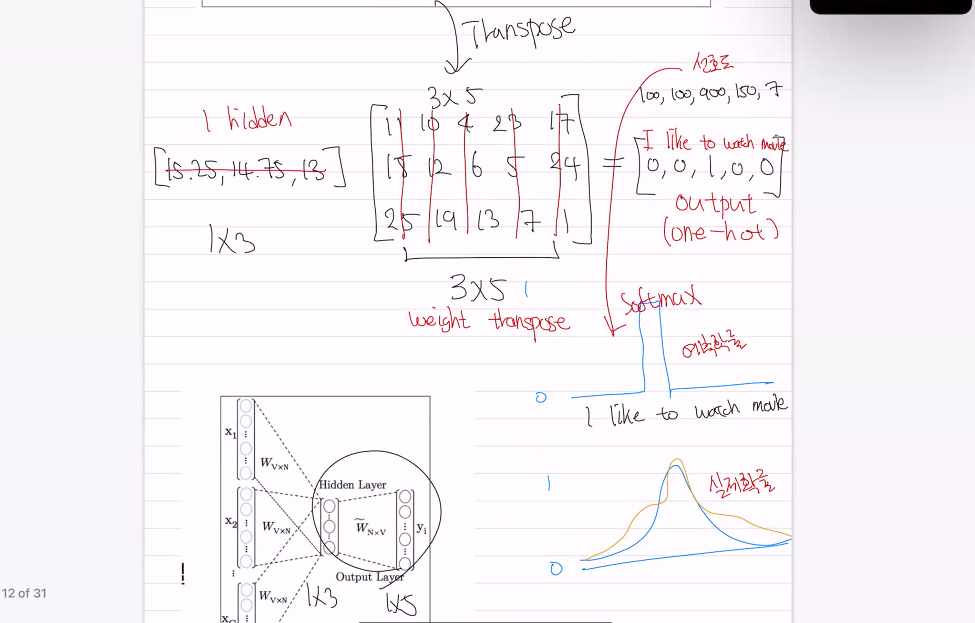
•주변 단어를 One-hot 인코딩 형식으로 주고, 중간의 단어를 예측해보자 예시: I like to watch movies중간 단어: to 주변 단어: I like / watch moviesI like ___ watch movies •각 화살표는 행렬 곱을 의미함 V = 단어 수 N = 히든레이어 크기다층 퍼셉트론W = 단어에 따른 가중치 -> 임베딩 행렬각 행마다 단어 임베딩이 있음
•각 화살표는 행렬 곱을 의미함 V = 단어 수 N = 히든레이어 크기다층 퍼셉트론W = 단어에 따른 가중치 -> 임베딩 행렬각 행마다 단어 임베딩이 있음(단어 위치가 달라도 동일)
 •V (단어 수) = 5•N (히든레이어 크기) = 3
•V (단어 수) = 5•N (히든레이어 크기) = 3

one hot vector는 4번째를 선택하는 결과과 됨


4번째거가 단순히 가중치

4번째가 단순히 가중치가됨
가중치가 모델이 보고있는
의미가 반영된 새로운 벡터
즉, 임베딩이됨
watch의 임베딩(가중치) 정확도가 모델학습 정확도에 영향

input --> hidden --> output
가중치를 transpose 해서 예측값을 구함

주변단어의 hidden layer끼리 평균을 냄



정보의 손실을 막기위해 embbeding 해서 새로운 벡터로 변경되서
모델이 생각하는 의미가 있는 가중치(단어)로 바꾼다.


hidden 값을 원핫으로 변경해야하는데
hidden size -> 가중치 transpose -> output (MLP) --> softmax(확률값) 해서 모델이 생각하는 중간단어의 확률
1x3 3x5 (5x3을transpose) 1x5
output값의 제일 높은 확률값이 input값의 to 였기 때문에 예측값은 to 이다.

결론
•Output에서는 주어진 주변 단어 임베딩의 평균을 가지고 중간 단어를 예측함
•실제 중간 단어의 확률이 가장 높도록 학습

Skipgram
•CBOW: 주변 단어를 주고 중간 단어를 예측해보자•Skipgram: 중간 단어를 주고 주변 단어를 예측해보자•여러 연구 결과 Skipgram이 보다 좋은 성능을 보여줌중간 단어를 갖고 주변단어를 예측을 하는것
•예시: I like to watch movies•___ ___ to ___ ___•Output 값은 V의 크기를 가지고 있음•이상적으로는 실제 단어의 One-hot 벡터가 되어야 함•하지만 실제로는 여러 단어들에 값들이 나누어져 있음



내적값 = 선호도

exponetiol = 자연상수 2.7...
exp(3) = e^3
어떤단어를 주어졌을때 다른단어를 예측하여야하니, 주어진단어랑 다른단어들의 임베딩 거리 계산하고,
주어진 단어가 학생이였을때,
주어진 단어가 무엇일까를 예측해봄.
거리가 멀면 낮은 선호도(확률), 거리가 멀면 높은 선호도(높은확률)

학생이 주어졌을때 학교의 확률을 계산함

임베딩 사이의 내적을 통해서 선호도를 구했는데
선호도를 바로 확률로 쓸수 없음
확률은 0부터 1사이라서
특정선호도가 전체 선호도의 합에서 차지하는 비율 --> 확률(학교|학생)


랜덤으로 단어를 뽑아도 효율적으로 계산할수 있음.
성능 저하가 거의 없음.

문제점: 관사가 많이나옴 --> 해결책 인위적으로 줄여줌

많이 나온 관사,전치사 이런 자주나오는 큰의미없는
단어를 인위적으로 학습빈도를 줄임
전체 단어비율이 차지하는 비율이 건너뛸 확률 -> 예) 100%중 30%

 •Subsampling을 통해 학습 속도를 향상시킬 수 있음•또한 드물게 등장하는 단어들에 대한 표현력 또한 증가함 -> 질 좋은 embedding이 만들어짐
•Subsampling을 통해 학습 속도를 향상시킬 수 있음•또한 드물게 등장하는 단어들에 대한 표현력 또한 증가함 -> 질 좋은 embedding이 만들어짐


의미 연산
한국과 서울과의 관계는
도쿄의 국가는 일본
한국 - 서울 + 도쿄 = 일본

원핫인코딩은 의미를 전달못해서 embedding을해서 의미를 포함


=================================================
'논문리뷰' 카테고리의 다른 글
아주대 - GTA Gated Toxicity Avoidance for LM Performance Preservation 논문리뷰 (2) 2024.09.18 [논문리뷰]DIP: Dead code Insertion based Black-box Attack for Programming Language Model (4) 2024.09.06 chapter01. n-gram 언어모델 (1) 2024.09.01 cnn 논문리뷰 (0) 2024.07.30