-
03_transformer 파해치기 https://nlpinkorean.github.io/illustrated-transformer/transformer 2024. 7. 12. 15:59
출처
https://product.kyobobook.co.kr/detail/S000200330771인용
Vaswani, Ashish, et al. "Attention is all you need." Advances in neural information processing systems 30 (2017).
출처
https://nlpinkorean.github.io/illustrated-transformer/
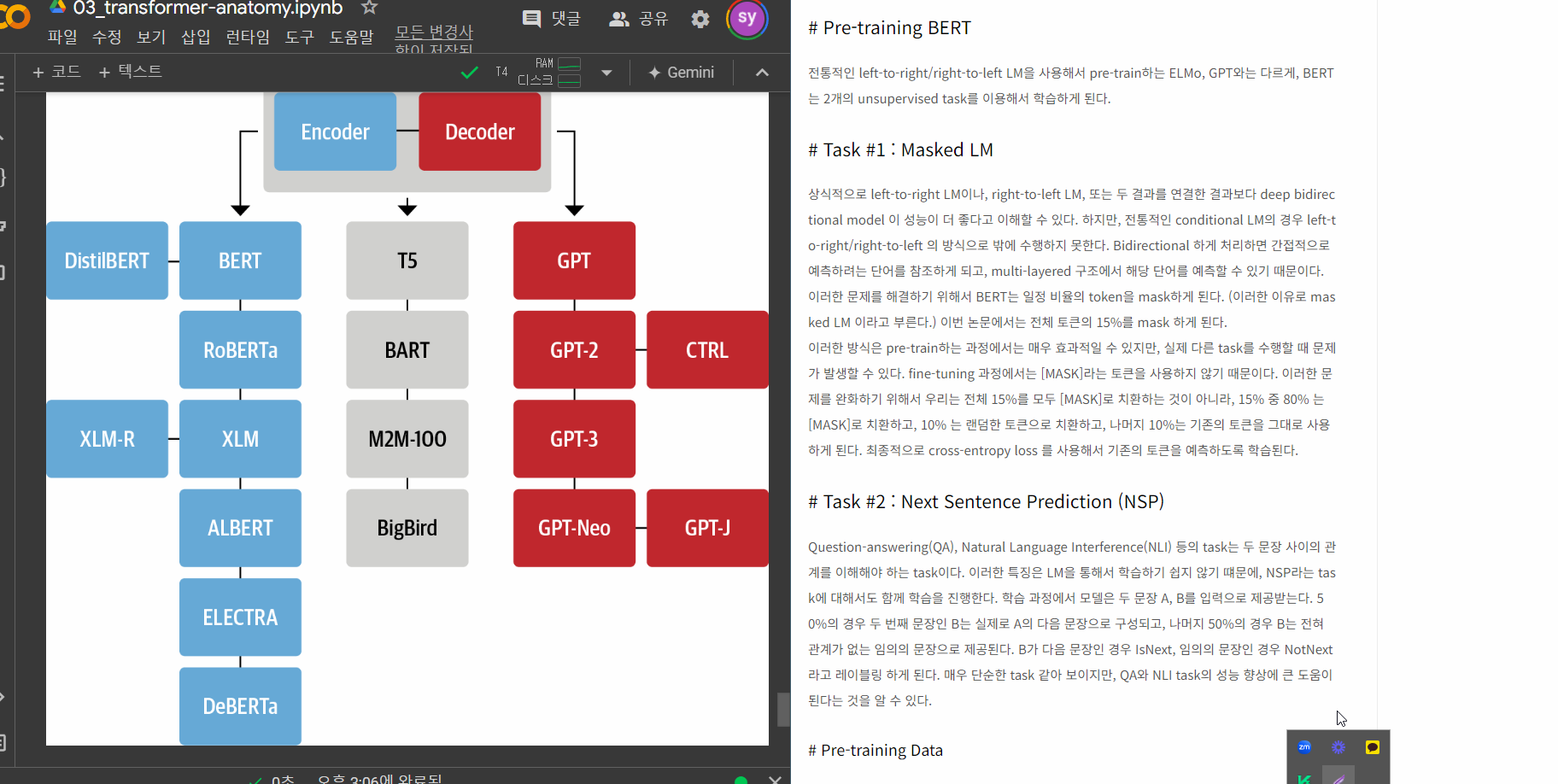
The Illustrated Transformer
저번 글에서 다뤘던 attention seq2seq 모델에 이어, attention 을 활용한 또 다른 모델인 Transformer 모델에 대해 얘기해보려 합니다. 2017 NIPS에서 Google이 소개했던 Transformer는 NLP 학계에서 정말 큰 주목을
nlpinkorean.github.io
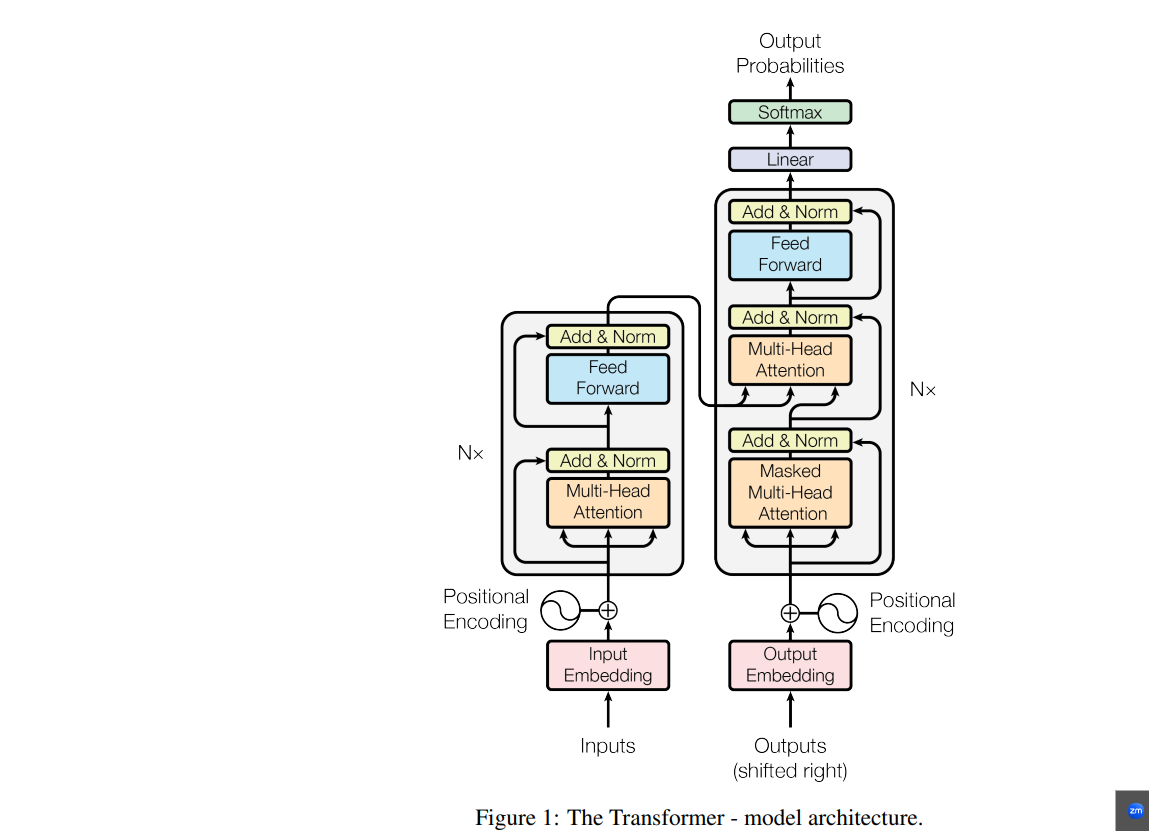
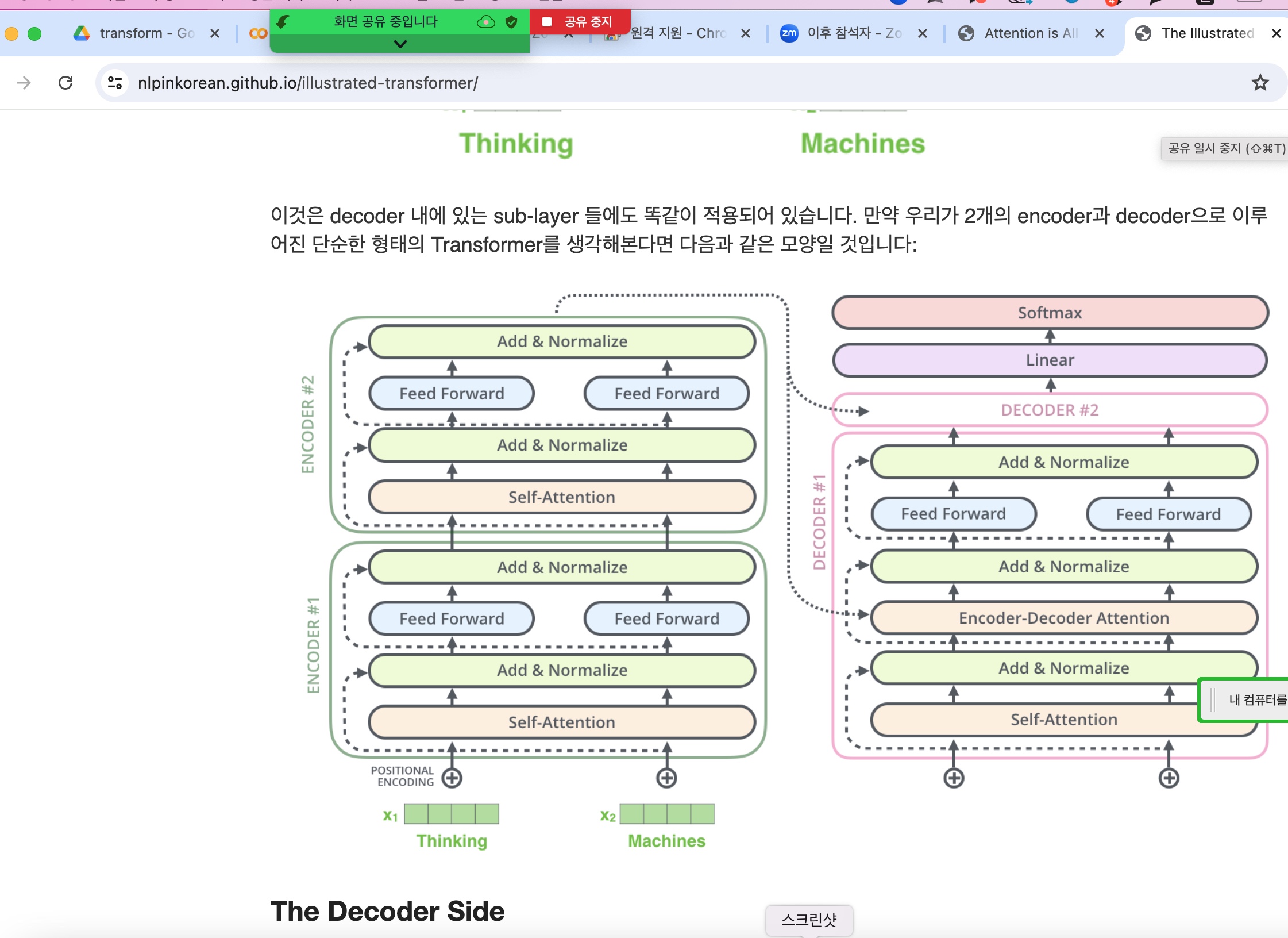
아래그림) transformer 구조 (위 논문 발표당시 인코더 6개, 디코더 6개)
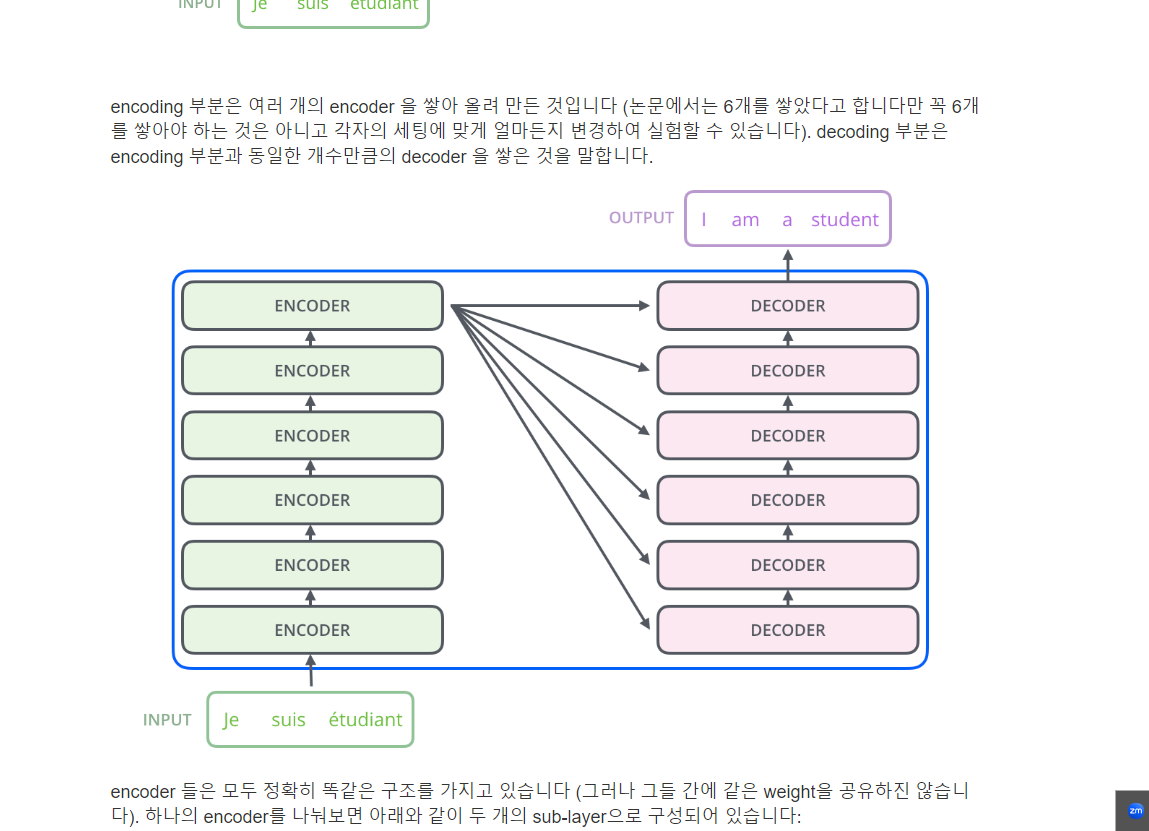
(아래그림) 하나의 인코드 구조는 self attention과 feed forward로 구성됨
아래그림) 디코더도 self attention과 feed forward로 구성되었는데 encoder-decoder attention이 하나 더있음

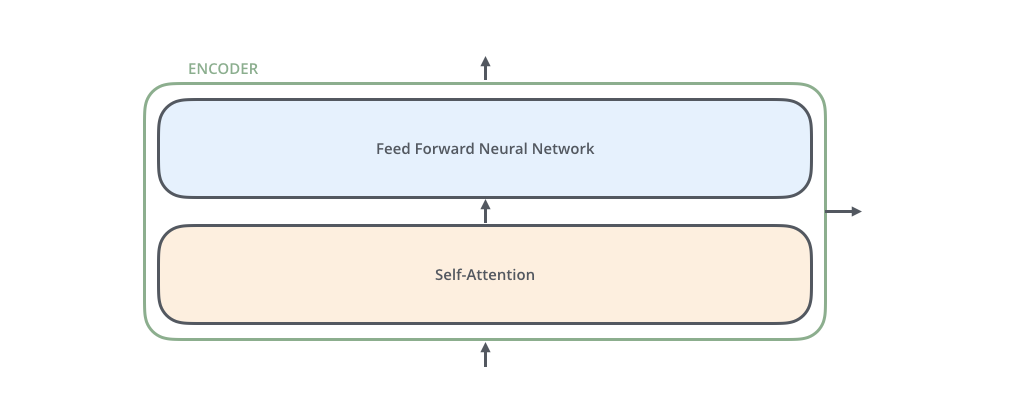
아래그림) encoder를 나오면 입력과 동일한 크기의 벡터가 나온다.

self attention이 중요해짐
그 동물은 길을 건너지 않았다 왜냐하면 그것은 너무 피곤했기 때문이다”
의 번역에서 그것은은 그동물인지 다른단어인지 헷갈릴수 있기 때문
아래그림) encoder의 it은 the animal 에 self attention됨

아래그림 self attention 과정

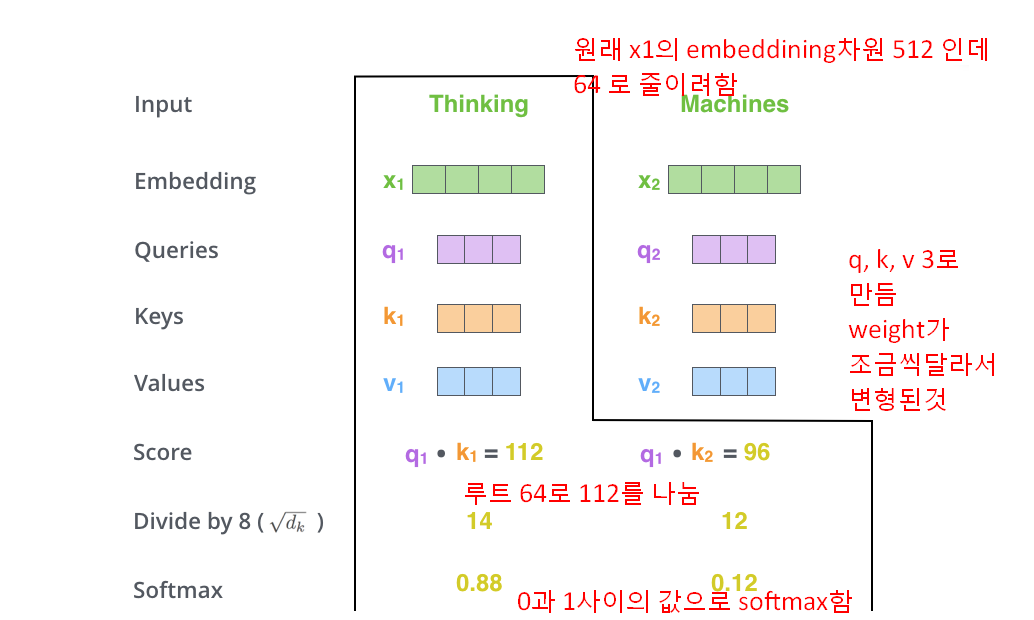
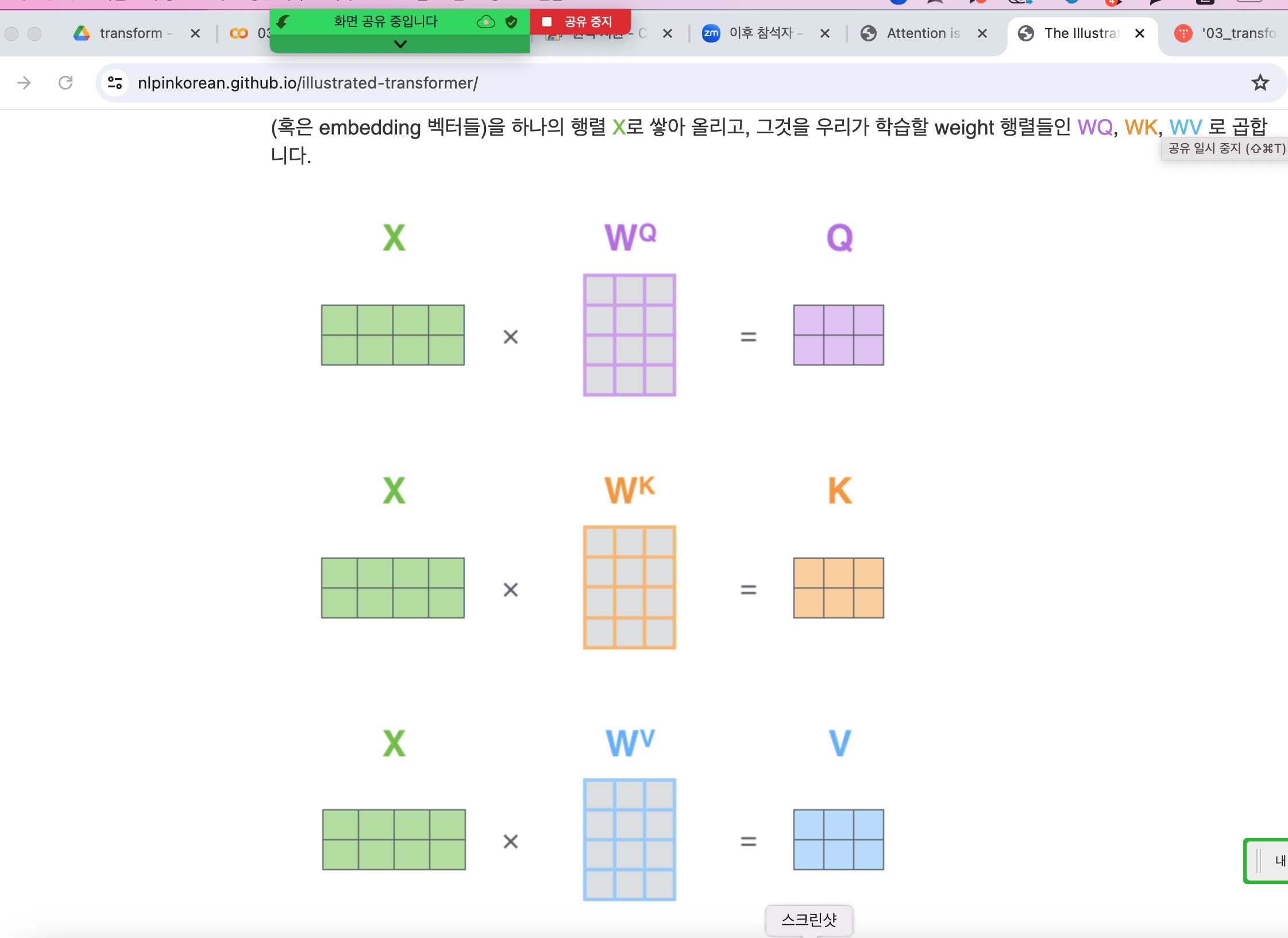
아래그림) 원래 x1의 embedding 차원이 512인데 64로 줄이려하고, x1을 weight를 조금씩 달리해서 q,k,v 3개로 만든후
q*k =112(q, k를 내적해서) 112를 루트 64로 나눈후 softmax해서 0과 1사이값으로 만듬
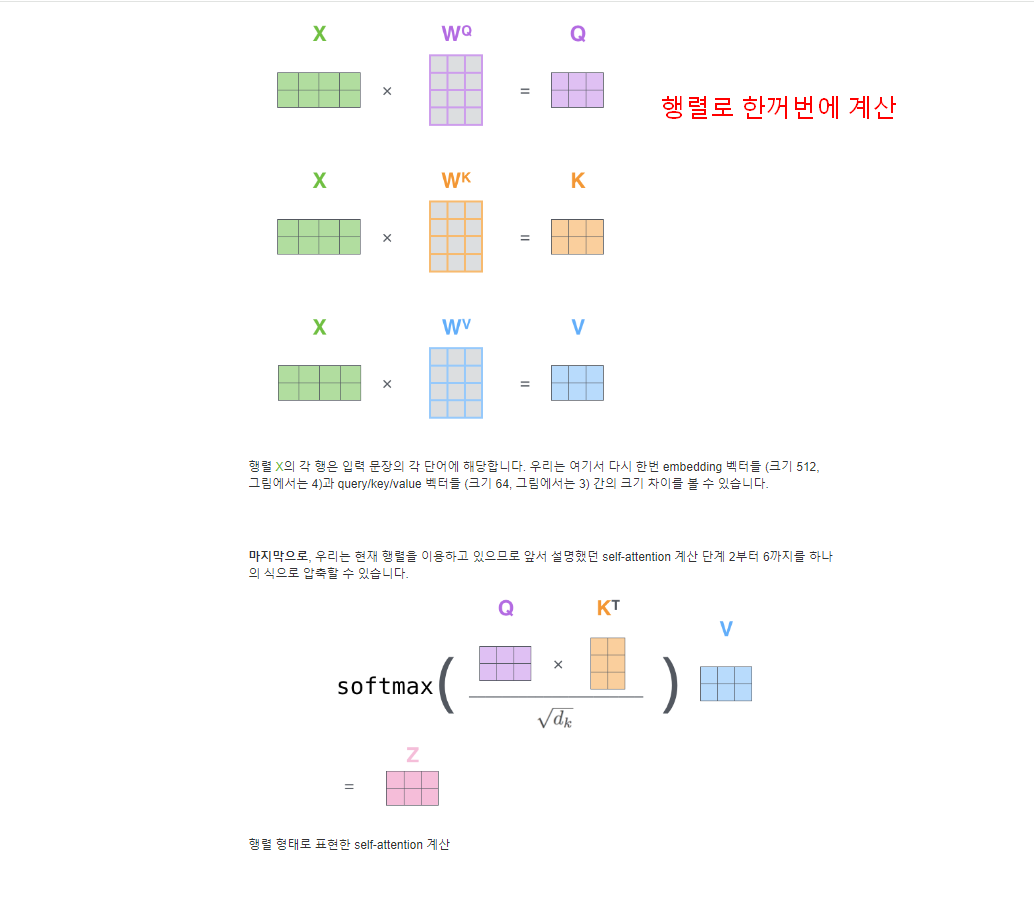
아래그림 ) 행렬로 한꺼번에 계산
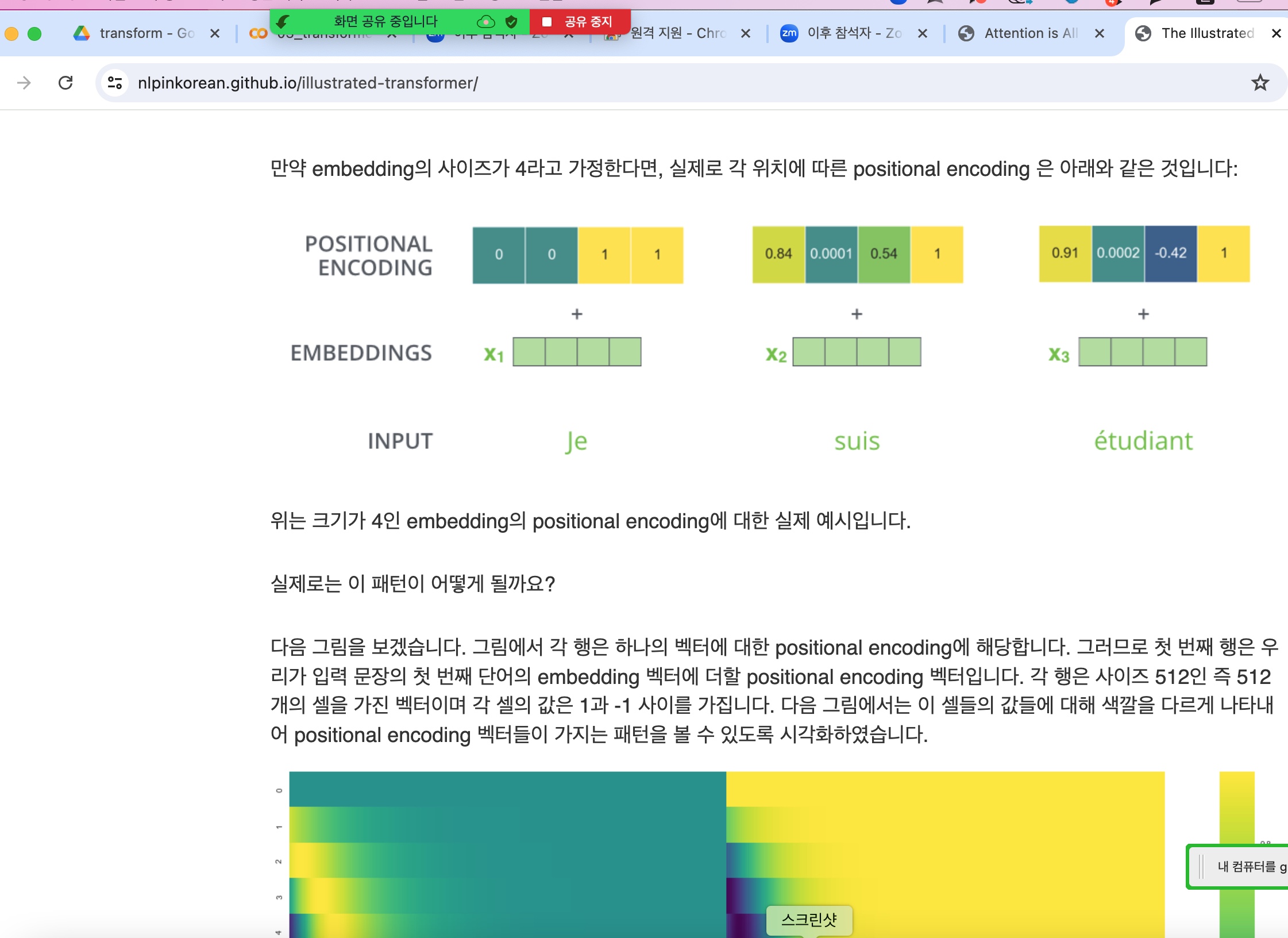
(아래그림) Embedding vector 에 positional encoding 를 합해서 단어의 위치정보를 같이 넣어준다.

(아래그림) positional encoding 위치정보를 절대적 정보로 넣어준다.
(아래그림) skip connenction(residual connection) 을 하면(점선) 긴 시간이 안들어서 최적화를 할수 있다.
(아래그림) 경로상에 너무 여러 연산이 있으면 backpropagation 시에 곱하는 항이 너무 많아져서(1/10*1/10 ...)
vanishing gadient 문제가 생길수 있다.

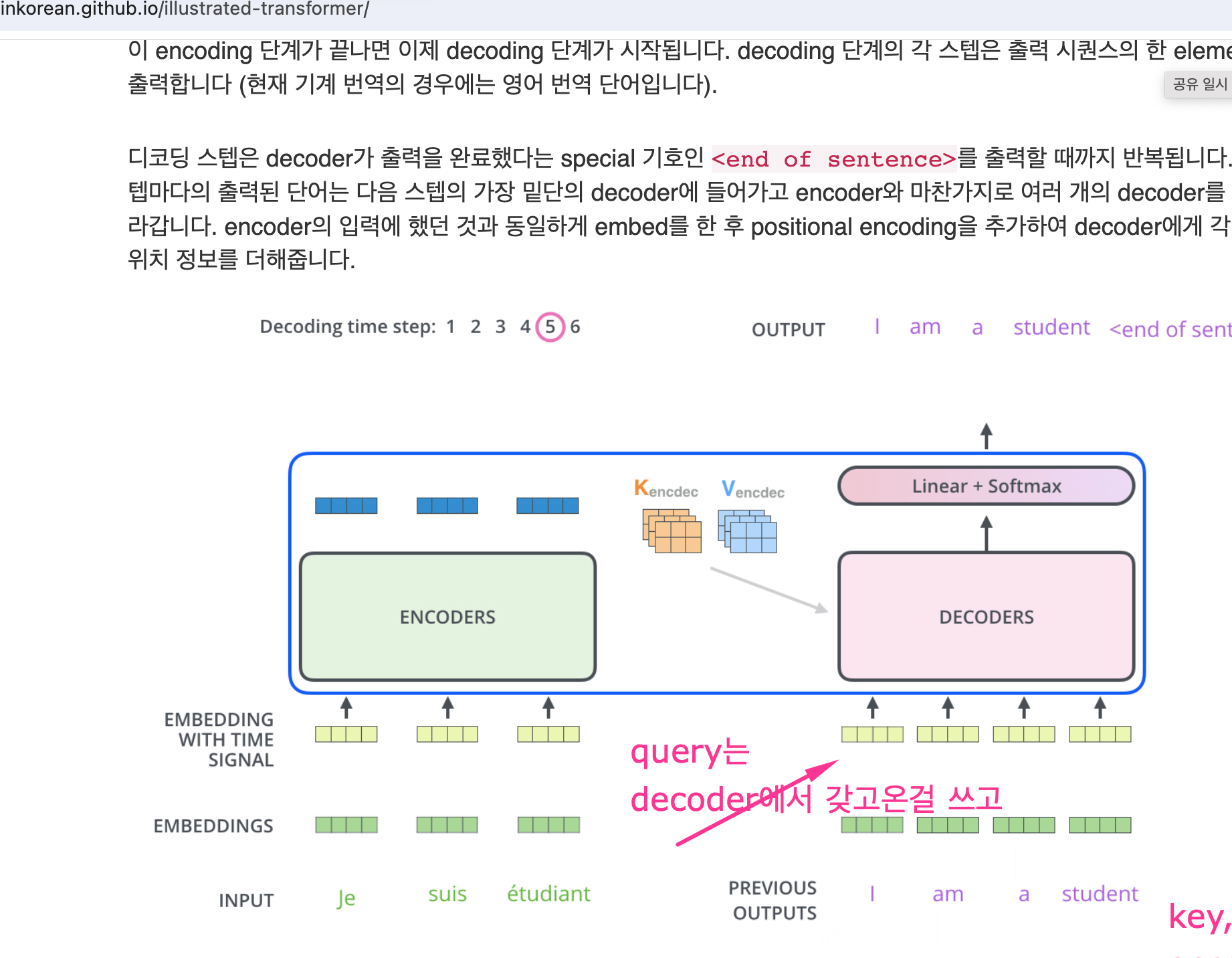
(아래그림) 원래 embedding은 q, k, v 가 x를 살짝만 바꾸니까 같은 x에서 와서 의미가 됨.(query, key, value)
아래그림) query는 decoder에서 새로운걸 받고, key, value는 encoder에서 갖고온걸 쓴다.

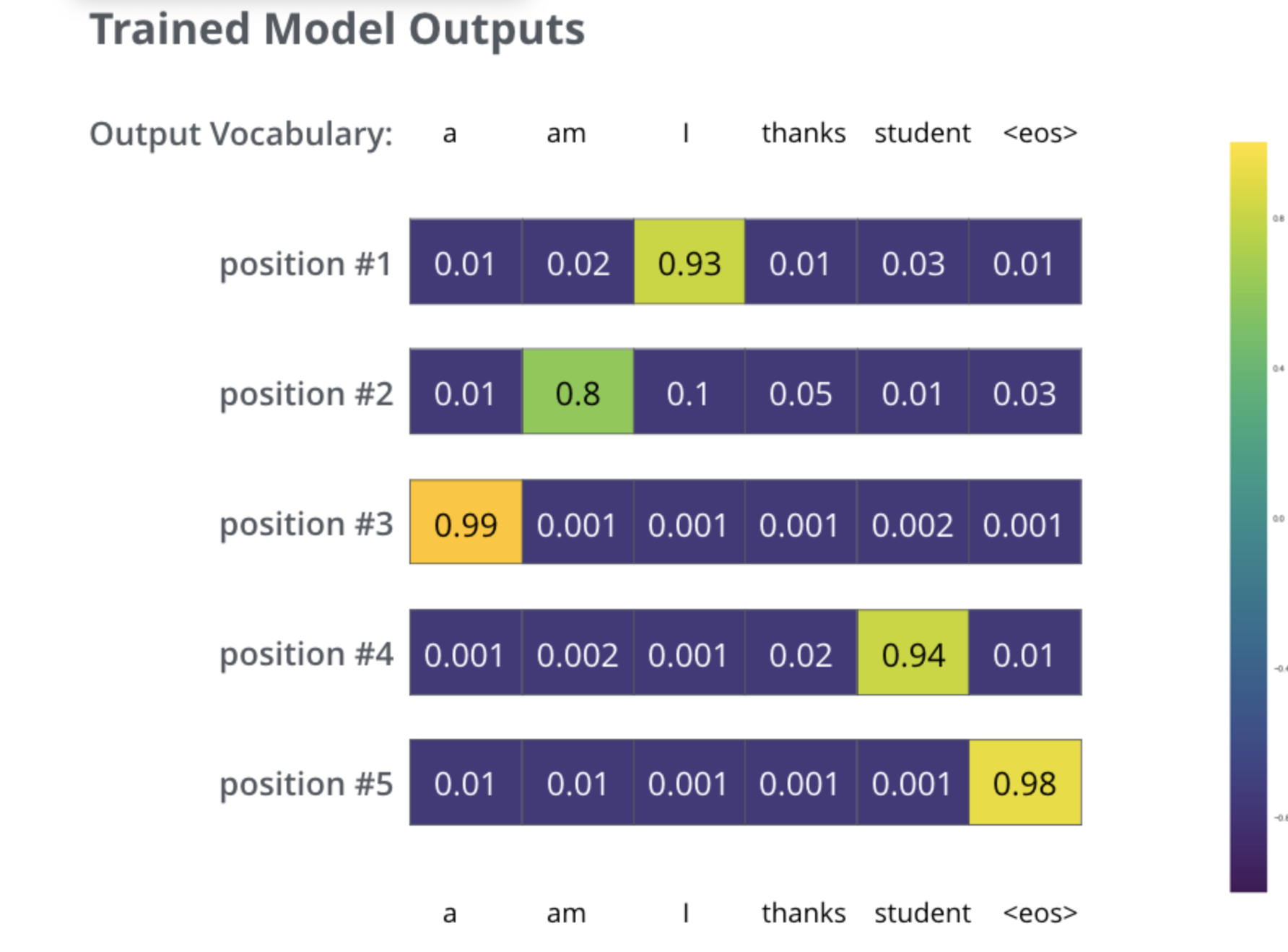
(아래그림) decoder를 지나서 linear(vocabsize로 변경) + softmax(확률값 0과 1값 로 바꿈)
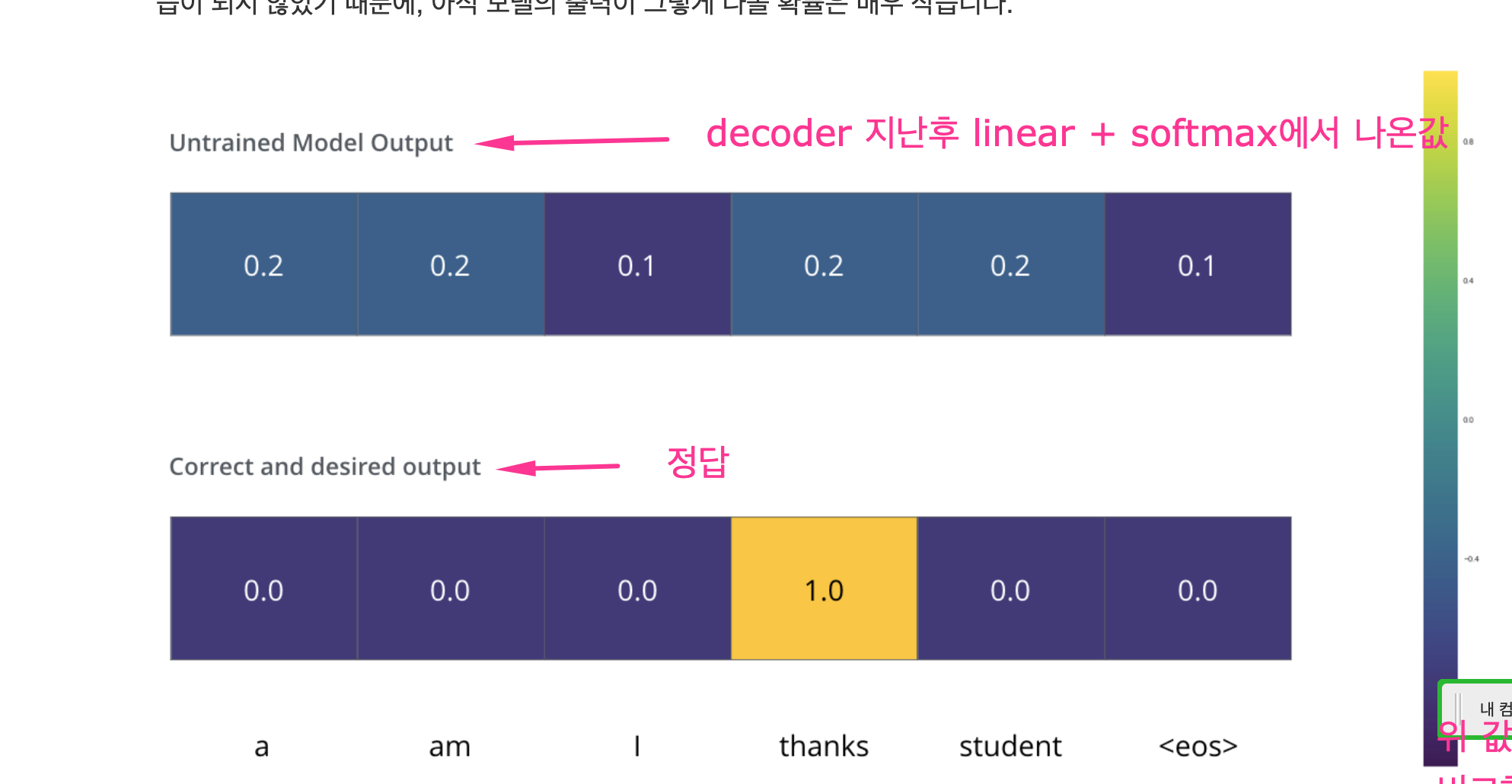
아래그림) 정답과 linear + softmax에서 나온값을 비교하는것을 crosentropy를 쓴다.
그다음과정 ) backpropagation으로 학습시킨다.
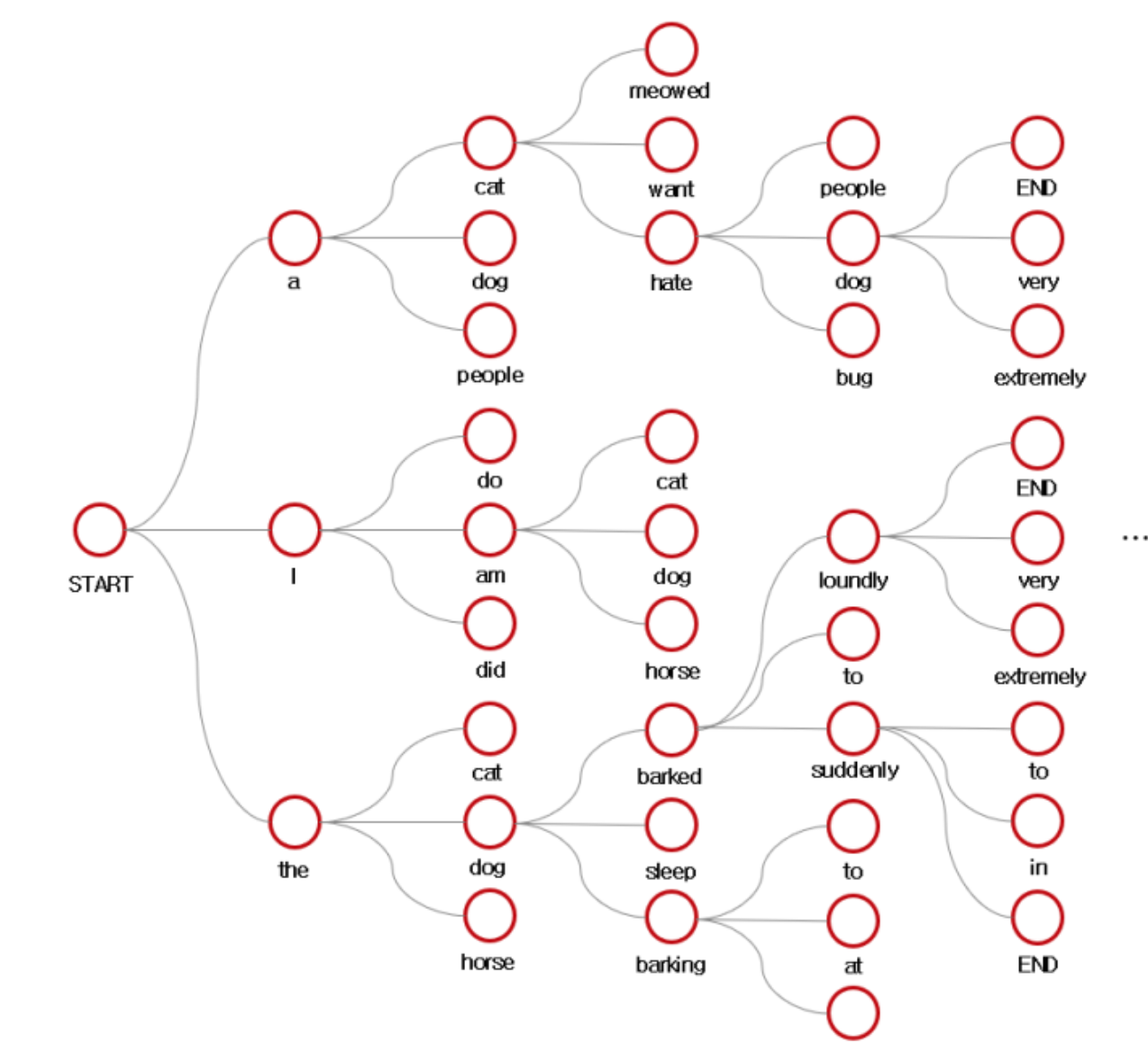
(아래그림) 우리는 모델이 가장 높은 확률을 가지는 하나의 단어만 저장하고 나머지는 버리는 greedy decoding,가장 확률이 높은 두 개의 단어를 저장할 수 있음. 이것이 beam search
(아래그림) beam search

아래그림) 위수식을 코딩화한것

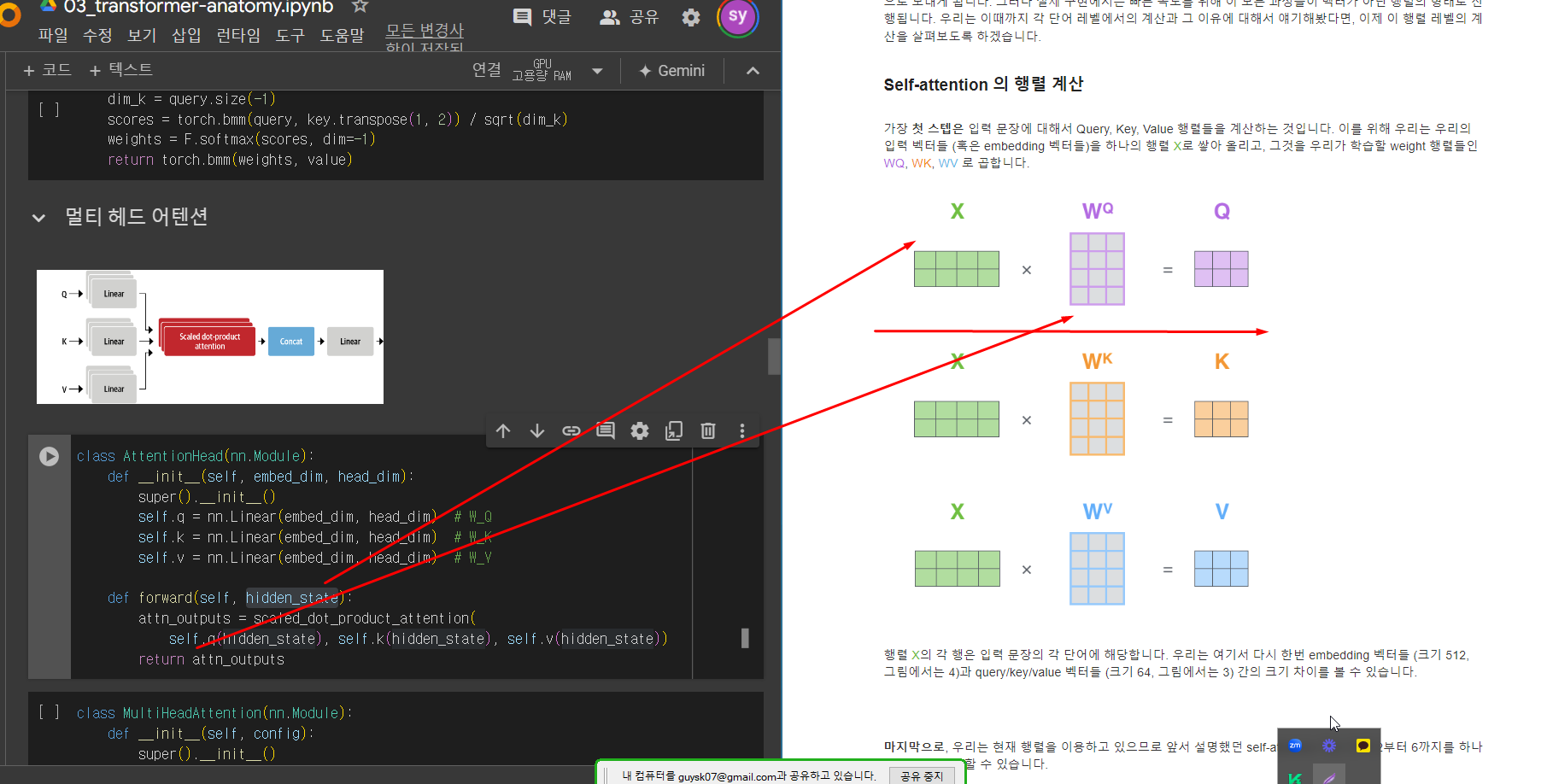
아래그림) self-attention의 행렬계산
self.q , self.k, self.r = w_Q, w_K, w_V
self.q * w_Q(hidden_state) = Q

아래그림) self.q(hidden_state(사실상 x) = X x W_Q

아래그림) self.q(hidden_state(사실상 x) = X x W_Q
(아래그림) 1과 곱해지는 수는 사실상 행렬내적
onehot vector 는 vocab size (1이 단어 하나) - 1이 가르키는 단어가 vocab에서 몇번째 단어인지 가르킴

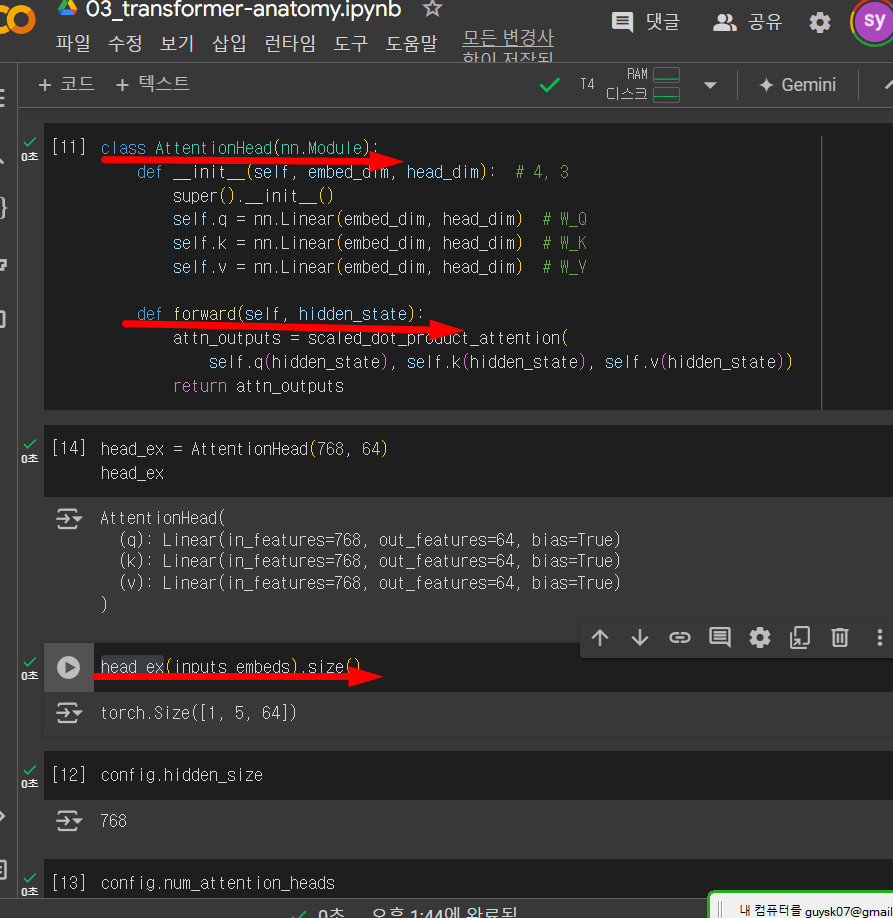
(아래그림) pytorch에서 nn(neural network) import

(아래그림) nn을 import한후 nn.Module을 상속받은후 forward 함수를 만드는데
이것은 (head_ex)인스턴스를 생성후 head_ex(inputs_embeds).size() -> 이렇게 매개변수를 넣으면
forward함수의 hidden_state를 통과하는것과 같다.
(아래그림)
h1(hidden) 이 z하나

(아래그림)
z를 나열한것이 torch.cat
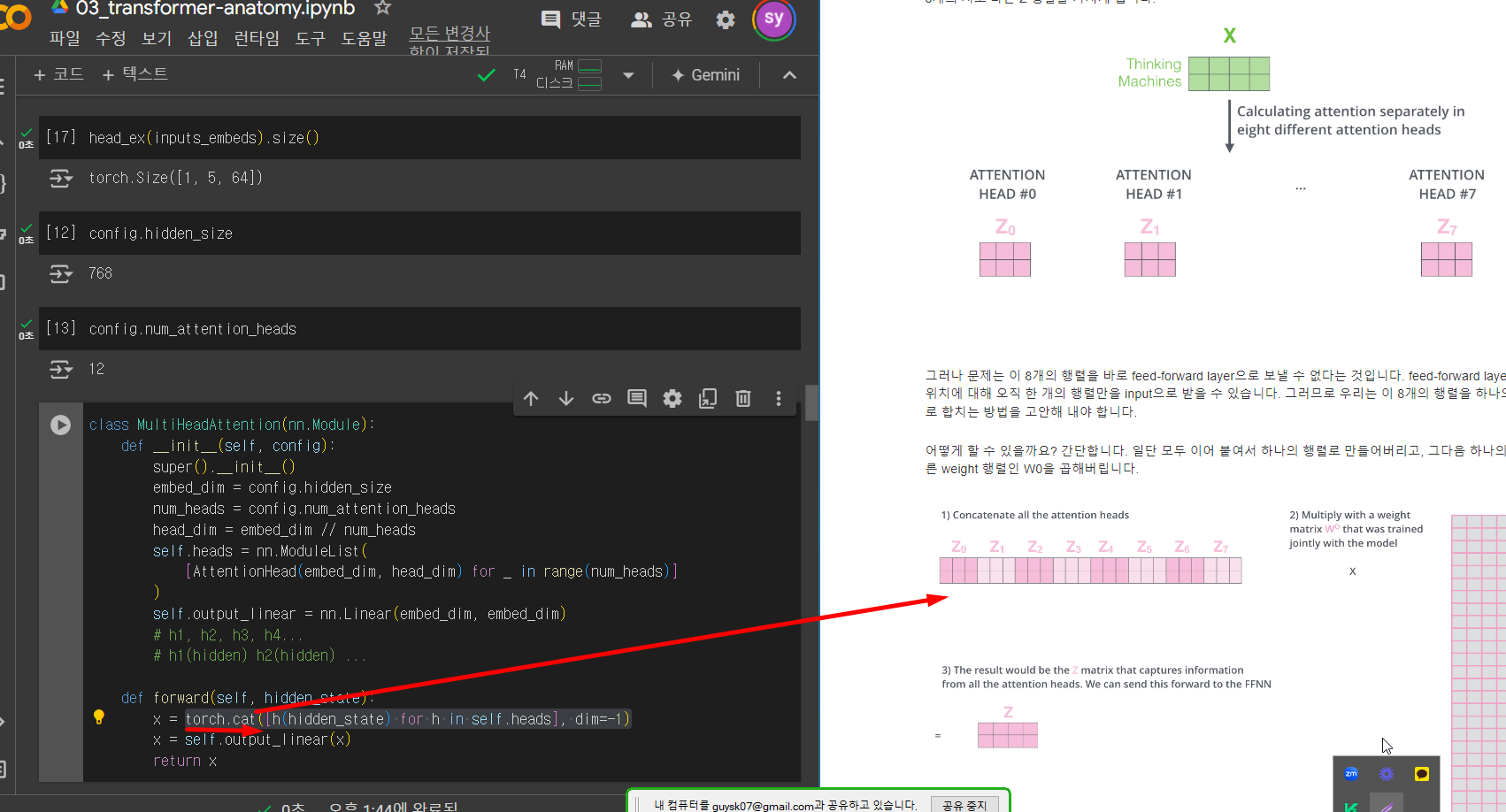
(아래그림)
self.output_linear = nn.Linear(embed_dim, embed_dim) 라고 선언한후
x = torch.cat을 다시 self.output_linear 에 통과시킨다(곱한다).

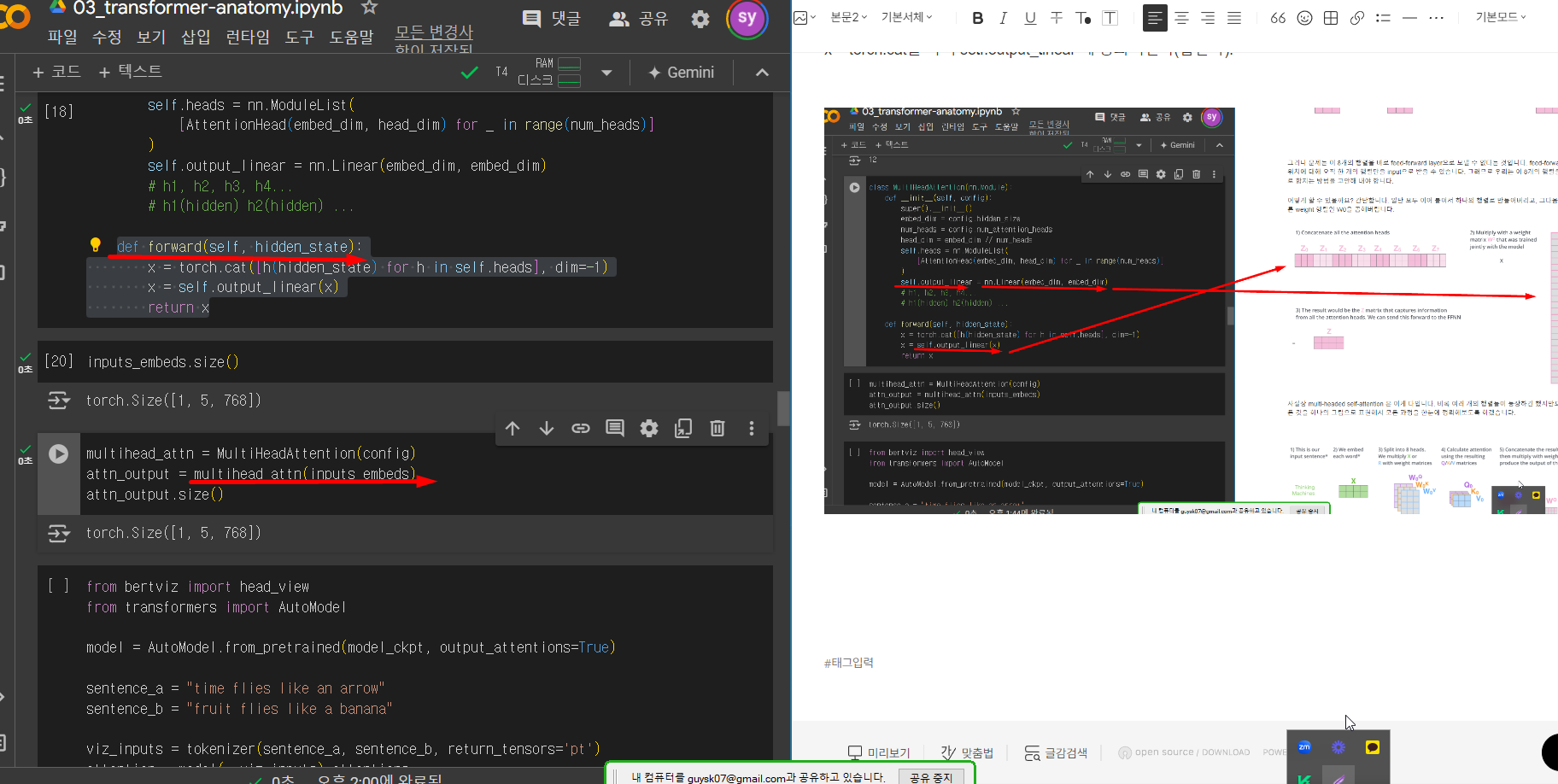
(아래그림) multihead_attn 인스턴스를 만든후 inputs_embeds가 hidden_state대신 매개변수로 들어가서 forward함수를 통과한다.
(아래그림) relu 함수를 보완한 함수인 gelu함수
출처 https://pytorch.org/docs/stable/generated/torch.nn.GELU.html

(아래그림) linear 층 통과후 gelu 활성화 함수 통과하면 dense layer(single layer perceptron 한층) 통과

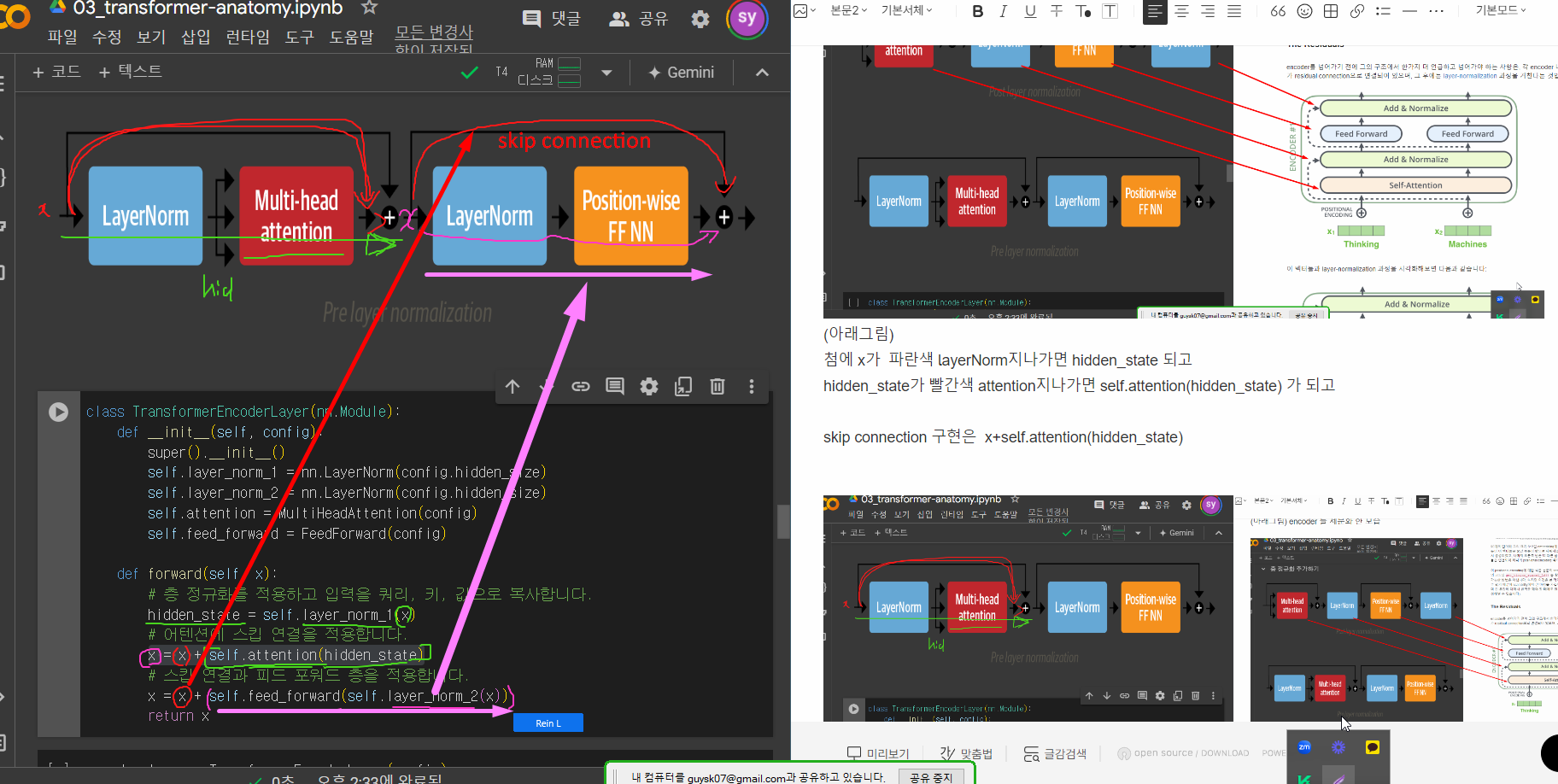
(아래그림) encoder 를 세분화 한 모습

(아래그림)
첨에 x가 파란색 layerNorm지나가면 hidden_state 되고
hidden_state가 빨간색 attention지나가면 self.attention(hidden_state) 가 되고
skip connection 구현은 x+self.attention(hidden_state)

아래그림)
encoder 내부에서
핑크 x 는 가운데 통과하는 텐서 x = x + self.attention(hidden_state)
파란색 layernorm 과 주황색 feed forward를 통과한것을 합한다.
x = x + self.feed_forward(self.layer_norm_2(x)) (여기서 2번째 x는 attention을 지난 x)
'transformer' 카테고리의 다른 글
05_text-generation.ipynb (0) 2024.07.31 04_multilingual-ner.ipynb (0) 2024.07.26 F1 score (0) 2024.07.12 02. classification (0) 2024.07.06 글내에서 어떤단어가 제품,사람, 장소인지 알려줌회사나 조직인지 분류 하는 태스크 : ner (0) 2024.07.05